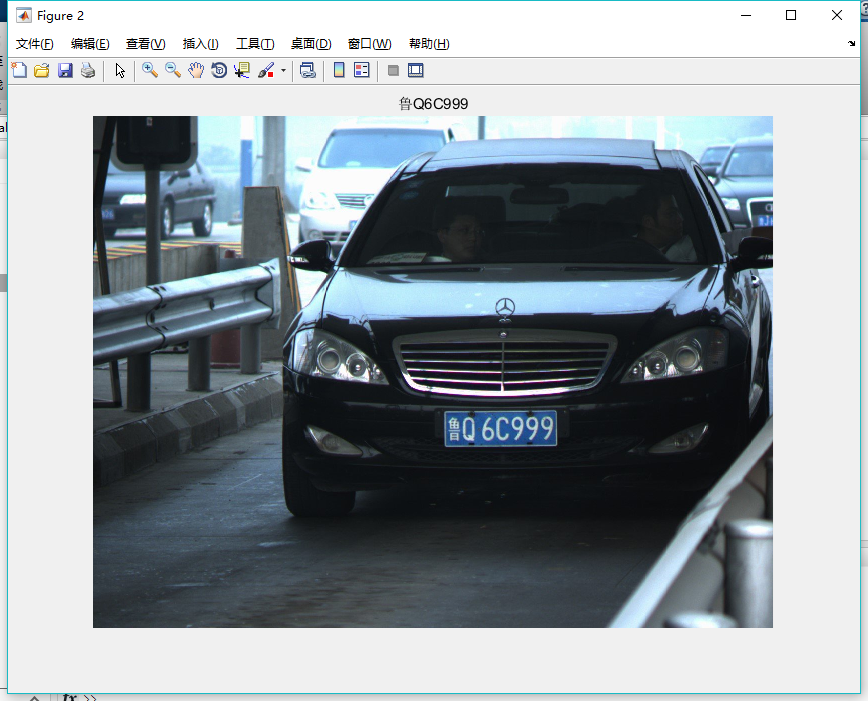
问题分析
车牌特点
样例车牌可以分为两类:
(1) 小功率汽车使用的蓝底白字牌照;
(2) 国外驻华机构使用黑底白字牌照
这些牌照的长度均为45cm,宽为15cm,共有字符7个。一般民用牌照第一个字符为汉字,且是各省市的简称;第二个字符为大写英文字母,如“E”;第三个字符是英文字母或阿拉伯数字,第四至第七个字符为阿拉伯数字。
实验流程
实验流程包括:车牌定位、倾斜校正、字符分割、字符识别4个部分
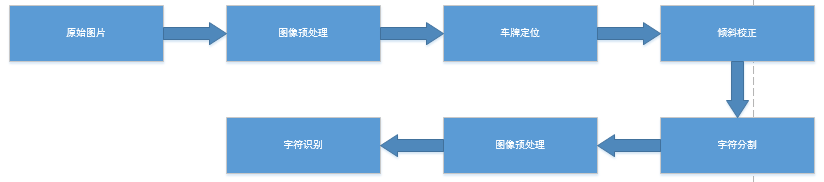
(1) 原始图像:样例中所给的汽车图像;
(2) 图像预处理:对原始图像进行二值化等预处理操作;
(3) 车牌定位:定位出汽车牌照所在的矩形范围;
(4) 倾斜校正:对定位后的车牌进行倾斜校正;
(5) 字符分割:定位分割得到的车牌图像,得到单个的字符;
(6) 图像预处理:重新定义分割后的字符图像大小,并转化为一维矩阵;
(7) 字符识别:通过BP神经网络训练,得到最后的汽车牌照,包括英文字母和数字。
实验过程
解决思路
车牌定位
1) 基于灰度边缘检测与形态学重构的方法。这种方法只要利用车牌区域局部对比度明显和有规律的纹理特征来定位,然后利用形态学方法将车牌区域与其它背景区域分离。
2) 基于直线检测的方法。这种方法主要Hough变换的方法来检测车牌周围边框直线,利用车牌形状特性来定位车牌。
3) 根据车牌的固有长宽比进行定位的方法。因为中外车牌的长宽比都是固定的3.1:1,在预处理完成后对二值化的图像进行膨胀腐蚀,计算联通区域长宽比确定车牌位置。
4) 基于彩色图像的车牌定位方法。现在的牌照有四种类型:第一种是最常见的小型汽车所用的蓝底白字牌照;第二种是大型汽车所用的黄底黑字牌照;第三种是军用或警用的白底黑字、红字牌照;第四种是国外驻华机构用的黑底白字、红字牌照。基于彩色图像的车牌定位方法主要利用车牌颜色与车身其他部位颜色具有明显不同的差异来分割与提取车牌。
5) 目前较为成熟的车牌区域定位算法有自适应边界搜索法、区域生长法、灰度图像数学形态学运算法、基于纹理或颜色的分割方法以及模糊聚类法等。
字符分割
1) 投影分析常采用的是水平投影法。即沿水平方向计算每一列属于车牌字符的象素数目,在字符的间隙处取得局部最小值,分割位置应在其附近。先根据车牌水平投影的统计特征呈现出明显“波峰——波谷——波峰”,进行水平方向上的粗分割,若字符出现合并和粘连现象,再采用递归回归办法进行二次字符分割。
2) 投影法进行字符分割实现起较为简单,但在预处理效果不好的情况下,较难获得满足条件的列。若增加预处理,则使处理后的图像不可避免地损失一部分有用信息,还可能导致额外误差。基于连通域聚类分析切分车牌字符的方法按照属于同一个字符的像素构成一个连通域的原则,结合牌照字符的固定高度和间距比例关系等先验知识,较好地解决了汽车牌照在复杂背景条件下的字符切分问题,降低了对车牌定位准确度的要求,对不规范的车牌识别也具有一定的适用性。
字符识别
1) 模板匹配法是最简单的一种字符识别方法。将待识别字符经分割归一化成模板字体的大小,将它输入字符识别模块进行匹配。根据实际字符和模板图像之间匹配方差最小的原则,判定车牌图像字符所属类别。这种方法对于标准、规范的字符识别效果较好。但在复杂环境下的车牌字符会与理想模板字符不完全一致,这导致了识别结果存在较大误差。
2) 模版匹配法简单、成熟,但其自适应不强。对于字符有断裂和粘连等情况容易造成误判。神经网络匹配法具有良好的容错性、自适应和学习能力,但样本的训练收敛速度慢,而大规模并行处理为此提供了解决途径。其中一种方法是采用并行识别的BP网络,让汉字、英文、阿拉伯数字,阿拉伯数字分别送到各自的网络识别。还有学者结合小波变化的优点,提出基于小波和BP神经网络的车牌字符识别新方法,采用小波变换提取字符特征,神经网络实现字符识别,加快了算法的执行,提高了识别率。
方法设计
车牌定位
1) 边缘检测方法
采用robert、prewitt、soble算子进行边缘检测,之后利用数学形态学的方法对边缘检测后得到的图像进行线性腐蚀、闭运算等操作得到初步定位的二值化车牌位置
2) 颜色提取方法
针对蓝底、黑底车牌,确定颜色提取的范围,进行颜色提取,提取后得到图像的逻辑矩阵,逻辑为真的部分为初步定位的二值化车牌位置
3) 根据行、列像素灰度值累积值确定行列起始、终止位置。
4) 将逻辑矩阵初步确定的车牌位置的外接矩形作为车牌最终定位位置
倾斜校正
1) 理想情况下,将车牌左上角,右上角连线与水平方向的夹角作为倾角。
2) 将定位后的车牌等分为左右两部分,求出平均y值,作为倾角。
字符分割
1) 水平投影法。沿水平方向计算每一列属于车牌字符的像素数目,在字符的间隙处取得局部最小值,分割位置应在其附近。先根据车牌水平投影的统计特征呈现出明显“波峰——波谷——波峰”,进行分割。
2) 首先计算列级灰度值,确定阈值范围,将满足阈值范围的列号设为逻辑真值1,用连续的两个0作为分割符,进行初步分割,对分割后的部分进行判断,取连续超过5个的逻辑真值列,作为分割后的字符位置。
字符识别
1) 使用matlab自带的bp神经网络进行训练
小组分工
描述小组成员的分工情况,每个人需要完成的任务
实现过程
牌照定位
边缘检测
首先采用边缘检测的方法进行定位,利用robert算子,进行边缘提取,之后利用腐蚀,闭运算填充的方法,得到初步的结果,之后根据车牌的大小,通过做差,提取出车牌部分
1 | a = imread('pics/2.jpg'); |

但是这种方法对于样例4,得到的结果并不理想

因此改用颜色提取的方法
颜色提取
根据蓝底和黑底车牌,确定不同的颜色范围,进行颜色提取。
以蓝底车牌为例:
1 | a = imread('pics/2.jpg'); |

确定范围
首先尝试通过行列的像素灰度值进行最终范围的确定,但得到的最终范围会损失一些有用信息,因此改用外接矩形的方法。
由于颜色提取后的车牌位置已经比较准确,所以将颜色提取后车牌位置的x,y轴极大极小值作为最终的范围

倾斜校正
(1) 在理想情况下,由于车牌为矩形,可以通过车牌的左上角和右上角确定倾角。但在实际识别过程中,定位的车牌左上角以及右上角并不准确,导致倾角误差较大。
(2) 将定位后的车牌等分为左右两部分,求出平均y值,作为倾角。
1 | [y,x,]=size(I); |

字符分割
(1) 首先计算列级灰度值,确定阈值范围,将满足阈值范围的列号设为逻辑真值1,用连续的两个0作为分割符,进行初步分割,对分割后的部分进行判断,取连续超过5个的逻辑真值列,作为分割后的字符位置。
先对定位后的图像进行再次抠图,得到更精确的逻辑矩阵,之后设立一维矩阵selectcol,如果列级灰度值的范围在(2,20),则将selectcol对应的列置为1
1 | a = DW; |
之所以要将范围下限设置为2,是为了排除一些干扰,由于下一步的分割要用连续的两个0作为分割符,但是对于图片五来说,第四个和第五个数字‘0’上方出现了车牌铆钉的干扰,如果不设置下界,则第四个和第五个数字被识别为连续的部分,不能进行分割。

分割
以连续的两个0作为分割符,并且只取长度超过5的部分(这是为了排除包括车牌中点号在内的干扰)
1 | [y,x,]=size(dd1); |
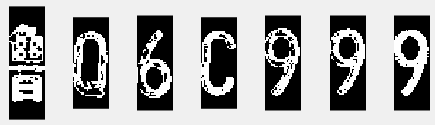

字符识别
建立模板库
模板库中包含部分字母以及数字
预处理
1 | function inpt = pretreatment(I) |
BP神经网络训练
1 | close all; |
结果呈现