Tensorflow
hello world
1 | import tensorflow.compat.v1 as tf |
1 | import tensorflow.compat.v1 as tf |
张量
所有的数据都通过张量的形式来表示
TensorFlow的张量和Numpy的数组不同,他计算的结果不是一个具体的数字,而是一个张量的结构。从上面结果来看,一个张量主要保存了三个属性,名字(name),维度(shape)和类型(type)
1 | #_*_coding:utf-8_*_ |
张量的第一个属性名字不仅是一个张量的唯一标识符,它同样也给出了这个张量是如何计算的,TensorFlow的计算都可以通过计算图的模型来建立,而计算图上的每一个节点代表一个计算,计算的结果就保存在张量之中。所以张量和计算图上节点所代表的计算结果是对应的。所以张量的命名就可以通过“node : src_output”的形式来给出。其中node为节点的名称,src_output 表示当前张量来自节点的第几个输出。比如上面的“add:0” 就说明了result这个张量是计算节点“add” 输出的第一个结果(编号从0 开始)。
张量的第二个属性是张量的维度。这个属性描述了一个张量的维度信息,比如上面样例中 shape = (2, ) 说明了张量 result 是一个一维数组,这个数组的长度为2。维度是张量一个很重要的属性,围绕张量的维度TensorFlow也给出了很多有用的运算。
张量的第三个属性就是类型(type),每一个张量会有一个唯一的类型。TensorFlow 会对参与运算的所有张量进行类型的检查,当发现类型不匹配的时候会报错
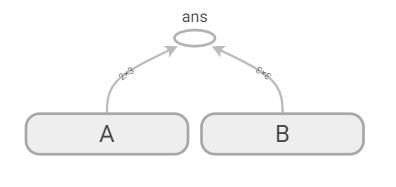
常量、随机数、变量
大规模常量张量对象最好定义成 t_large = tf.Varible(large_array,trainable = False)
可训练标志位为False
1 | t_1 = tf.constant(4) |
1 | #随机数 |
1 | rand_t = tf.random_uniform([50,50],0,10,seed=0) |


占位符
定义过程,执行时再赋具体值
1 | tf.placeholder(dtype,shape=None,name=None) |
常用函数
1 | (1)tf.argmax(input, axis=None, name=None, dimension=None) |
feed_dict
字符串拼接
1 | Str1 = tf.placeholder(tf.string) |
浮点数乘积
1 | Num1 = tf.placeholder(tf.float32) |
tensorboard
1 | import tensorflow.compat.v1 as tf |
logs上级目录下打开shell,命令: tensorboard --logdir "logs",新版tensorflow将 = 换成了双引号
更改命名空间:
1 | import tensorflow.compat.v1 as tf |