PyTorch实践
数据集处理
官方数据集
从PyTorch开源项目:vision或者text中加载数据集,对应的包是torchvision、torchtext
1 | #torchvision |
构建自定义数据集
1 | import torch.utils.data as Data |
细粒度构建自定义数据集
继承torch.utils.data.Dataset ,然后重载函数len,getitem来构建
1 | import torch.utils.data as Data |
1 | import torch.utils.data as Data |
加载数据集
使用torch.utils.data.Dataloader加载数据集
1 | tensor_person_data_loader = Data.DataLoader(dataset = person_dataset, |
加载自定义数据集:
1 | person_loader = Data.Dataloader(dataset = p, |
预处理数据集
通过__getitem__方法
1 | word2id = { |
通过collate_fn
1 |
|
模型
TorchVision支持一些经典模型
- Alexnet
- VGG
- ResNet
- SqueezeNet
- DenseNet
- Inception v3
TorchText没有统一模型
经典模型以及可视化
1 | import torch |
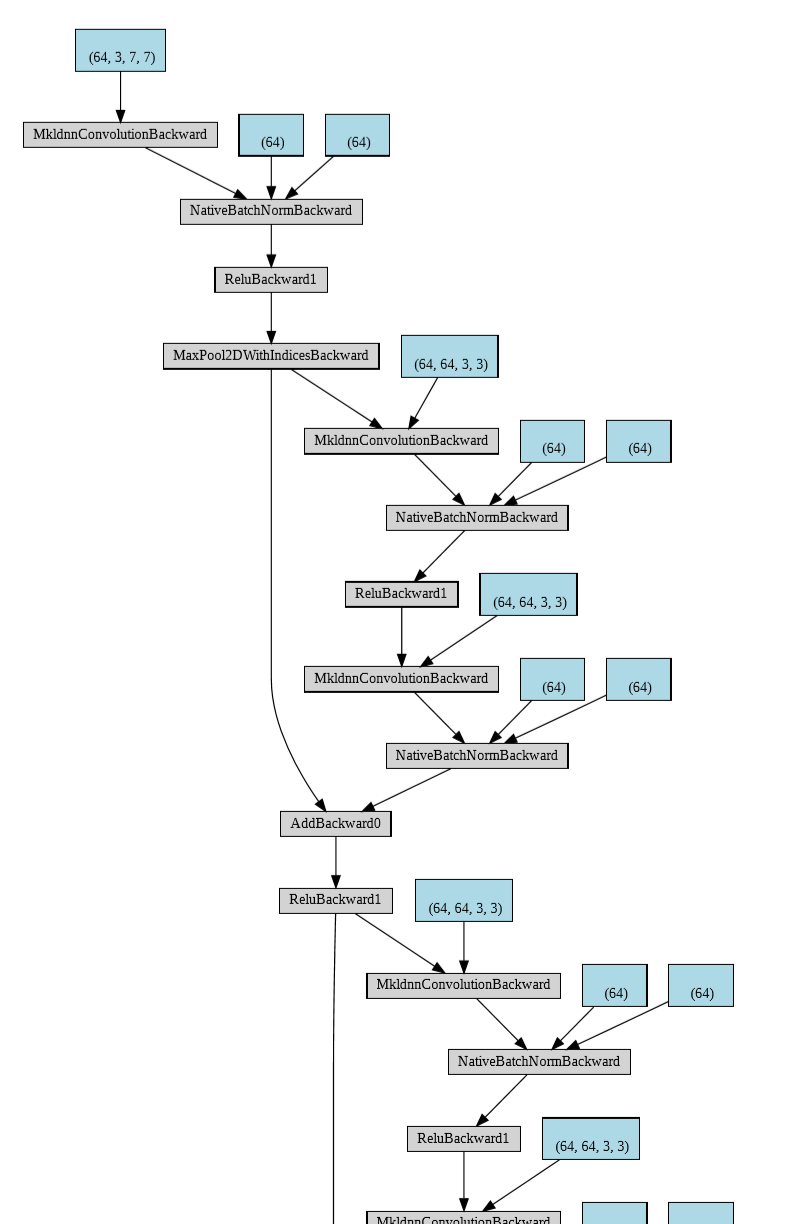
可以使用torchviz的方法进行可视化,会在目录下生成一个pdf文件
构建自己的神经网络结构
sample
1 | my_net = torch.nn.Sequential( |
构建多层网络
1 | hun_layer = [torch.nn.Linear(10,10) for _ in range(100)] |
深度自定义
1 | import torch.nn as nn |
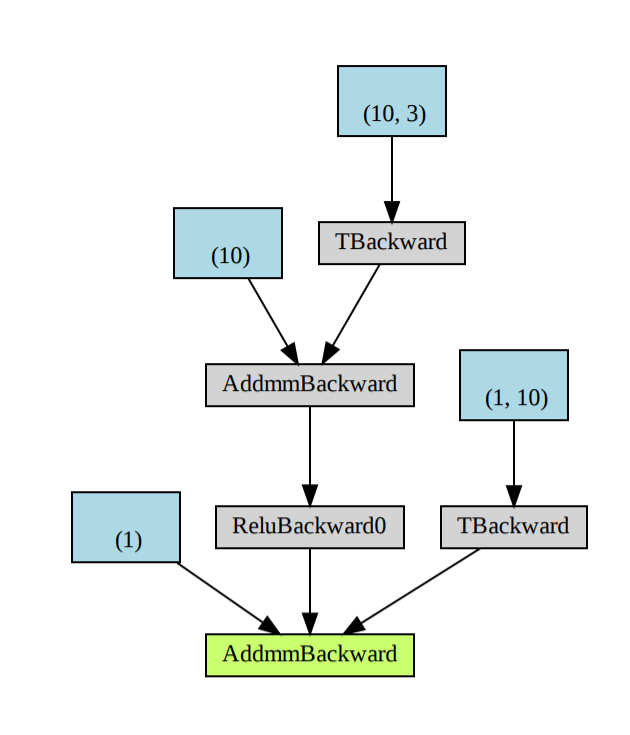
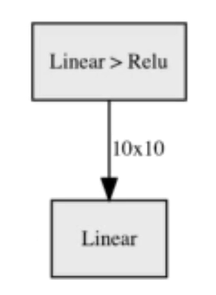
使用torchviz产生的可视化图不如hiddenlayer的简洁:
1 | for index,data in enumerate(person_loader): |
定义损失
官方定义的损失函数在两个地方
- torch.nn
- torch.nn.functional
torch.nn下面的loss函数,是作为模型的一部分存在,实际上是torch.nn.functional下loss函数的封装,实际上它还是调用了torch.nn.functional下面的函数
1 | a = torch.tensor(2.) |
损失函数
torch.nn.functional:
- binary_cross_entropy
- binary_cross_entropy_with_logits
- poisson_nll_loss
- cross_entropy
- cosine_embedding_loss
- ctc_loss
- hinge_embedding_loss
- kl_div
- l1_loss
- mse_loss
- margin_ranking_loss
- multilabel_margin_loss
- multilabel_soft_margin_loss
- multi_margin_loss
- nll_loss
- smooth_l1_loss
- soft_margin_loss
- triplet_margin_loss
如果要定义自己的损失函数,可以:
- 继承torch.nn.module实现loss(当成模型,计算图中的方块)
- 继承torch.autograd.function实现loss(当成函数,计算图中的椭圆)
实际区别在于谁去进行反向传播,官方实现中,loss是一个module
继承torch.nn.module实现loss
1 | class MyLoss(nn.Module): |
继承torch.autograd.funcion实现loss
适合损失函数非常难求导时
1 | from torch.autograd import Function |
实现优化算法
pytorch集成了常见的优化算法:
- torch.optim.Adadelta
- torch.optim.Adagrad
- torch.optim.Adam
- torch.optim.Adamax
- torch.optim.SparseAdam
- torch.optim.LBFGS
- torch.optim..RMSprop
- torch.optim.Rprop
- torch.optim.SGD
1 | from torch.optim import Optimizer |
如果自定义优化算法:
1 | class MyOptimizer(Optimizer): |
调整学习率
pytorch官方,提供了torch.optim.lr_scheduler类来基于动态调整学习率
- torch.optim.lr.scheduler.LambdaLR
- torch.optim.lr.scheduler.StepLR
- torch.optim.lr.scheduler.MultiStepLR
- torch.optim.lr.scheduler.ExponentialLR
- torch.optim.lr.scheduler.CosineAnnealingLR
- torch.optim.lr.scheduler.ReduceLROnPlateau
1 | from torch.optim.lr_scheduler import StepLR |
迭代训练
1 | import torch |
测试:
1 | will_u_be_single(torch.tensor([1.,1.,0.])) |
加速计算
1 | torch.cuda.is_available() |
储存和加载模型
储存整个模型:
torch.save(will_u_be_single,"./will_u_be_single.pkl")
加载整个模型:
model_from_file = torch.load("./will_u_be_single.pkl")
储存参数:
torch.save(will_u_be_single.state_dict(),"./will_u_be_single_2.pkl")
加载参数
1 | model_parameter = torch.load("./will_u_be_single_2.pkl") |