与CNN区别
CNN输入、输出相互独立
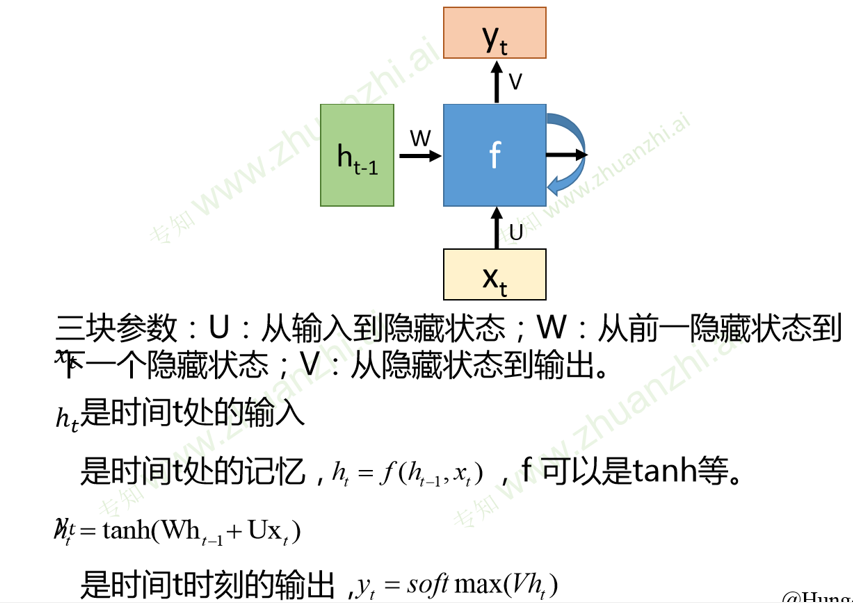
RNN可以更好地处理有时序关系的任务
RNN通过循环结构引入“记忆”概念(输出不仅依赖于输入,还依赖于记忆,将同一个结构循环利用)
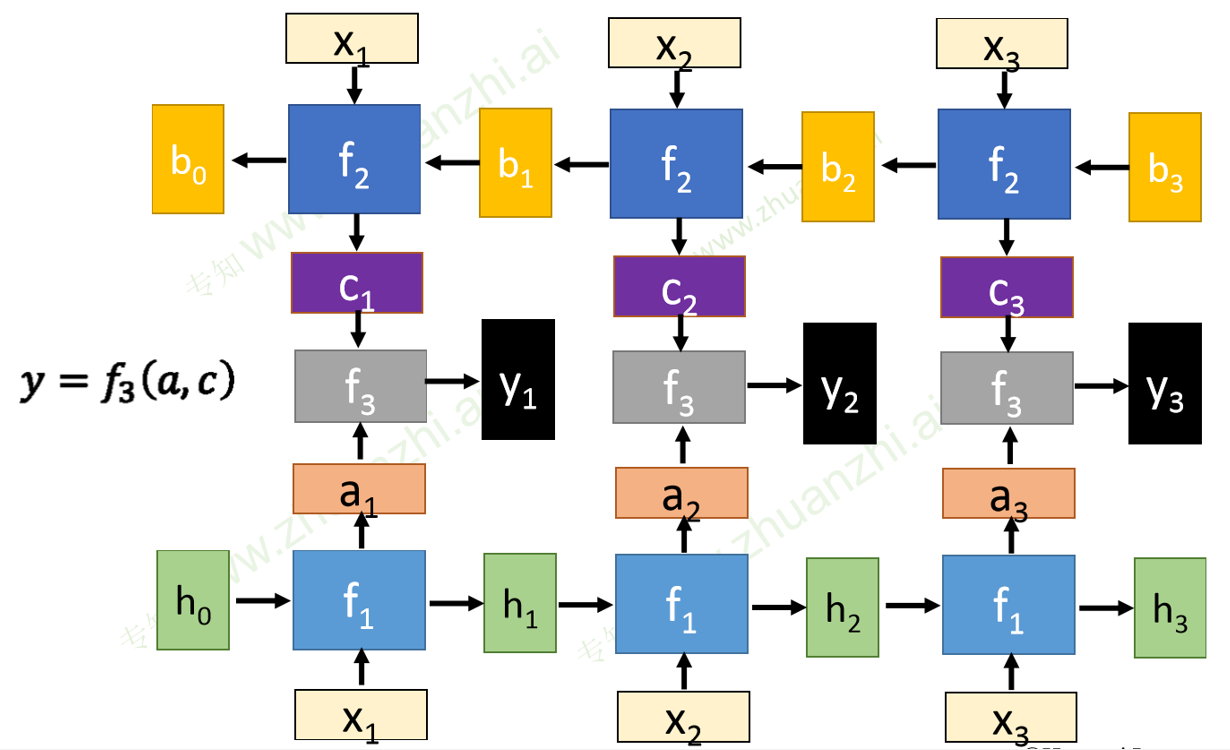
基本结构
深度RNN
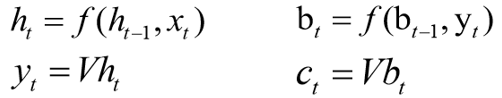
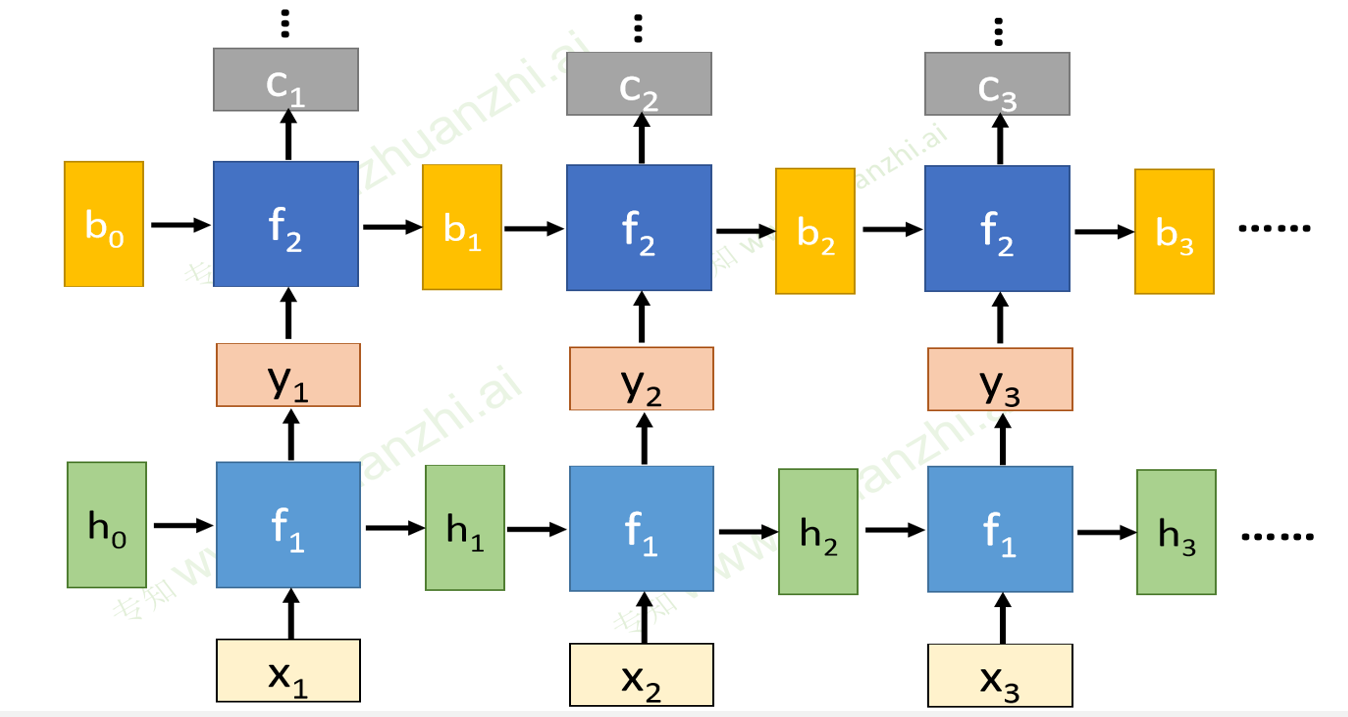
双向RNN
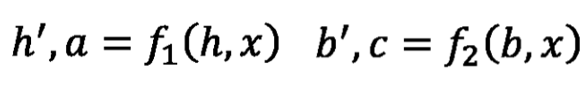
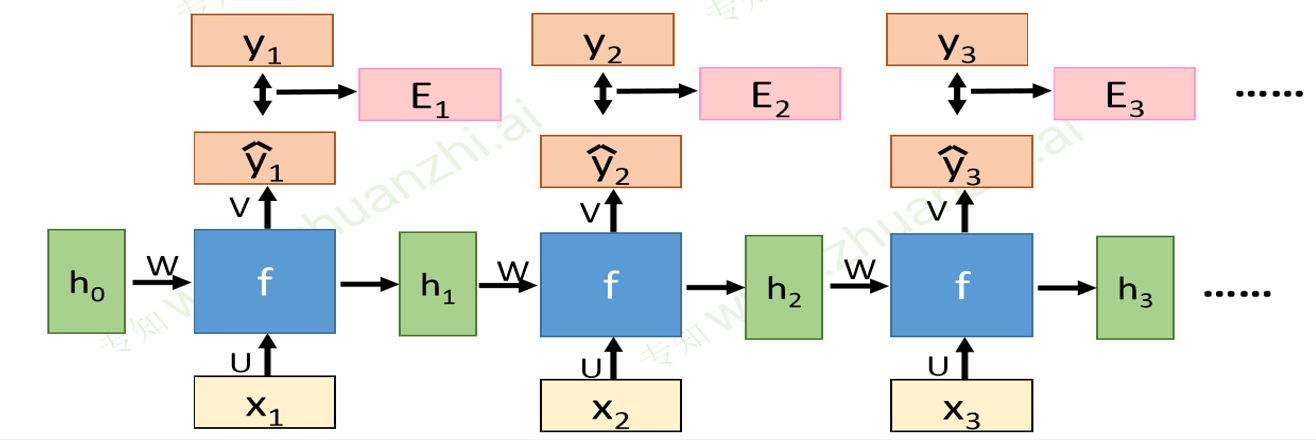
BPTT算法

每一个时刻t的损失,取输出的y与真实值的交叉熵
总损失为各个时刻t的总损失

由于h3与h2相关,具有时序关系,所以需要展开对h2求偏导,根据链式法则,得到偏导:

传统RNN问题
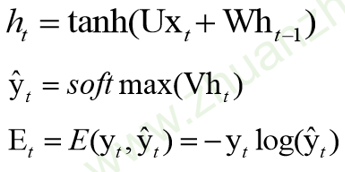
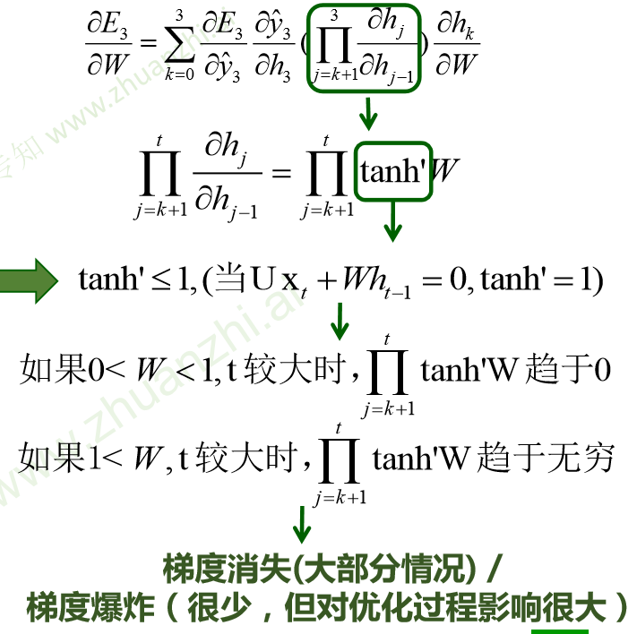
对权重求偏导,对于累乘项来说,当t比较大时,
- 如果0<W<1,梯度趋于0
- 如果W>1,梯度趋于无穷

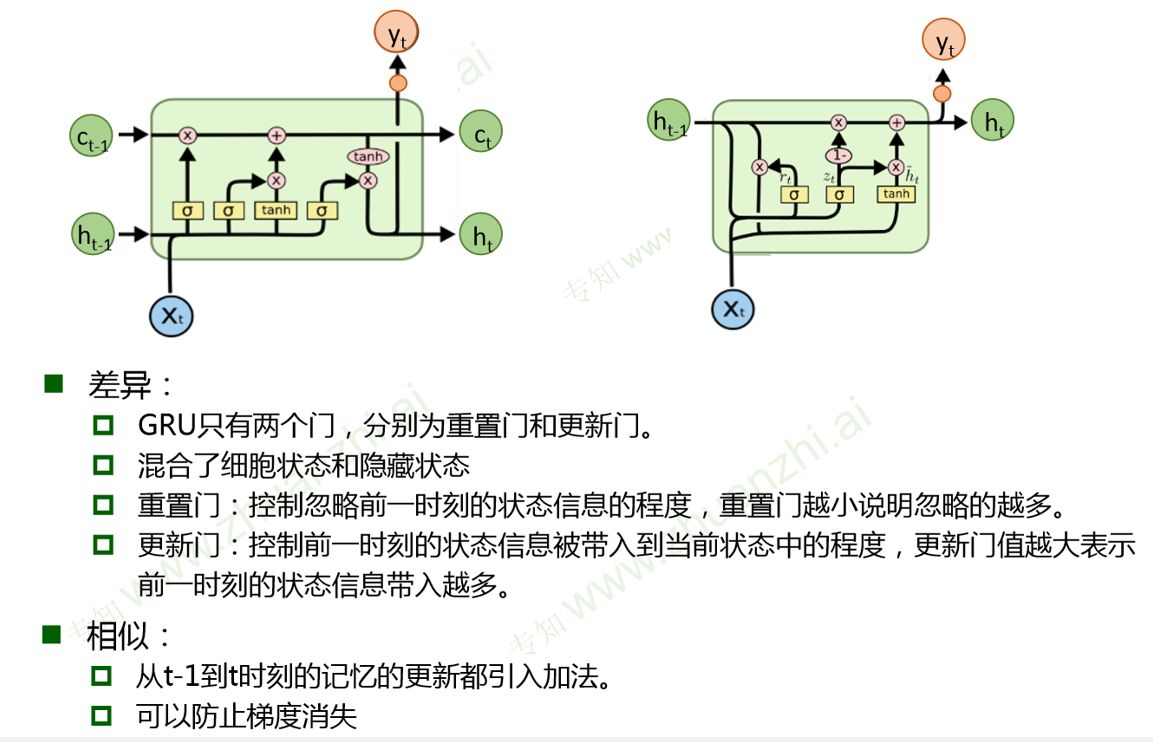
LSTM
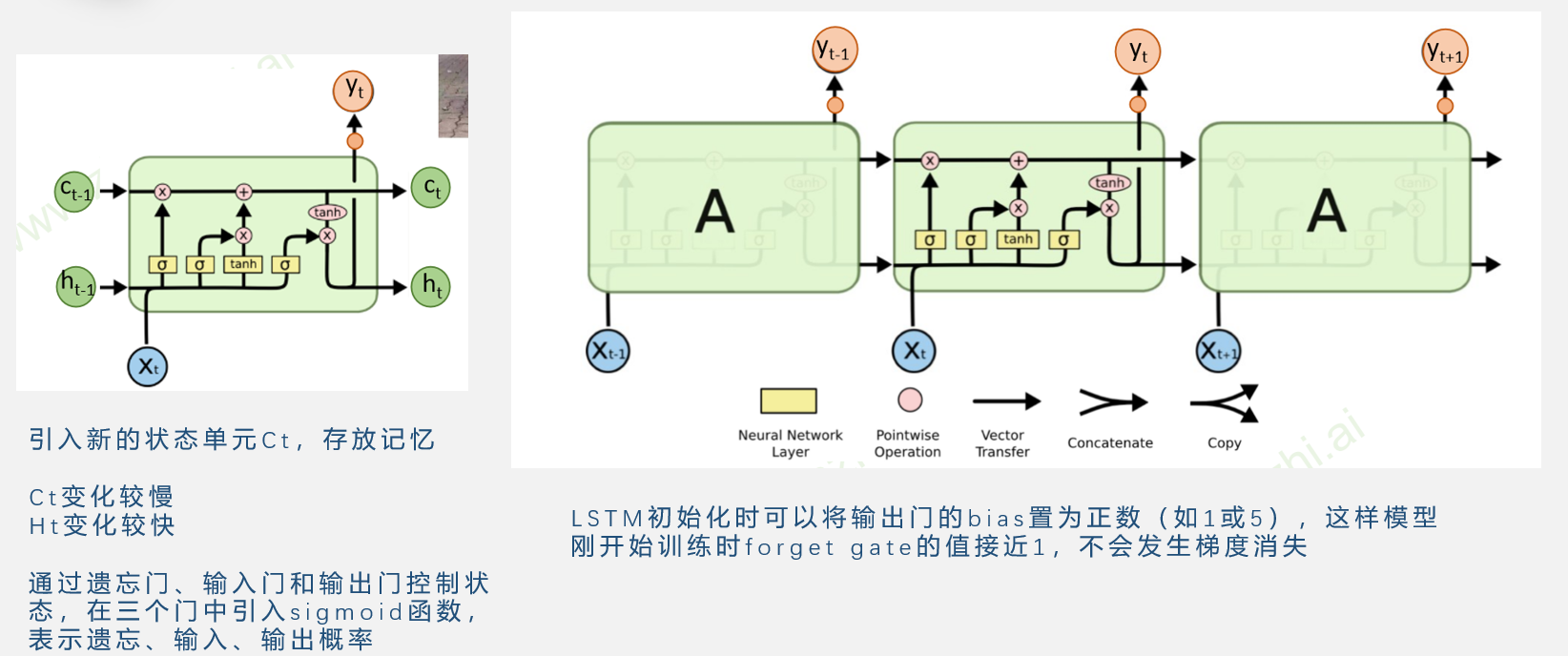
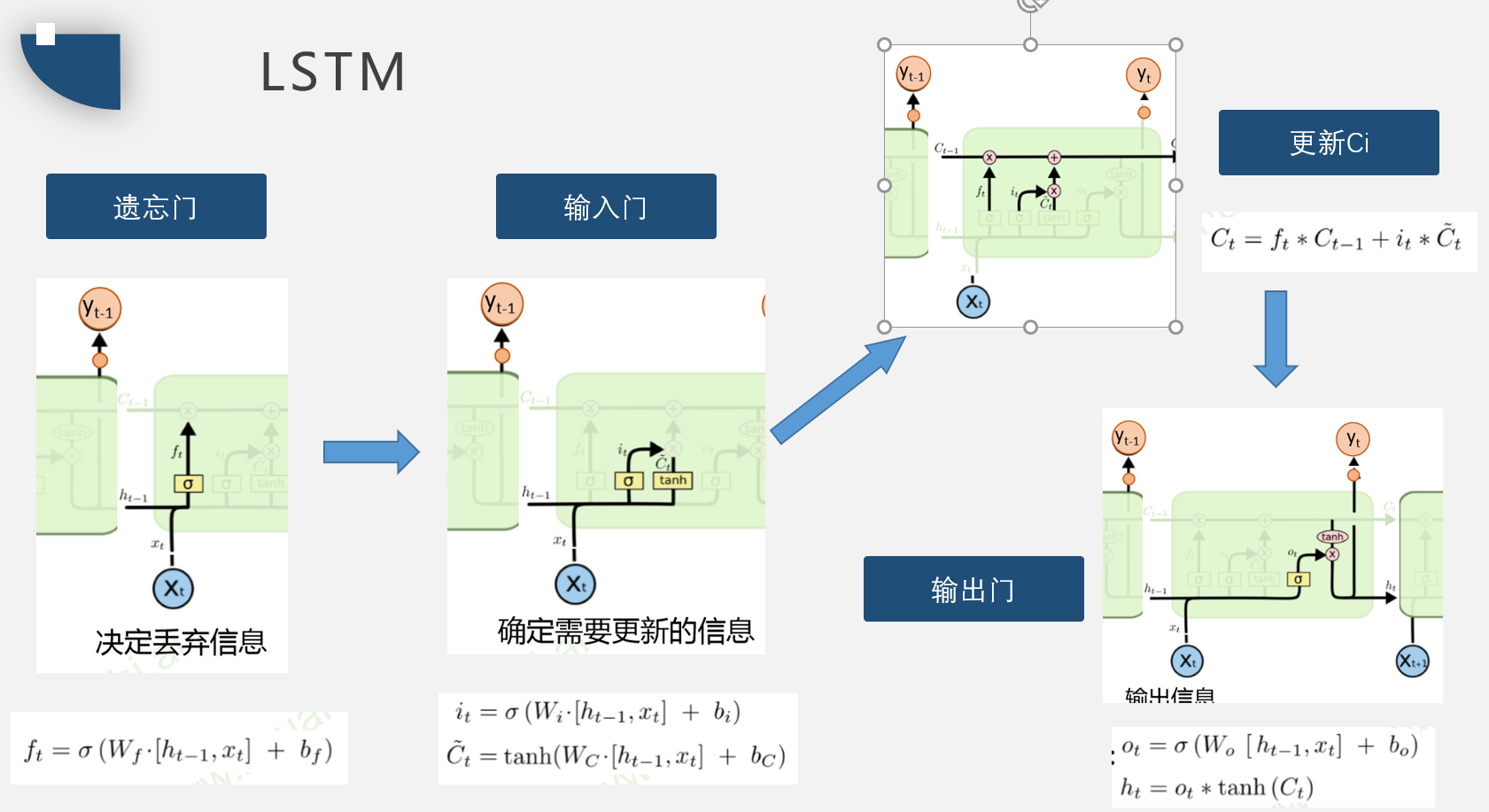
LSTM与RNN区别
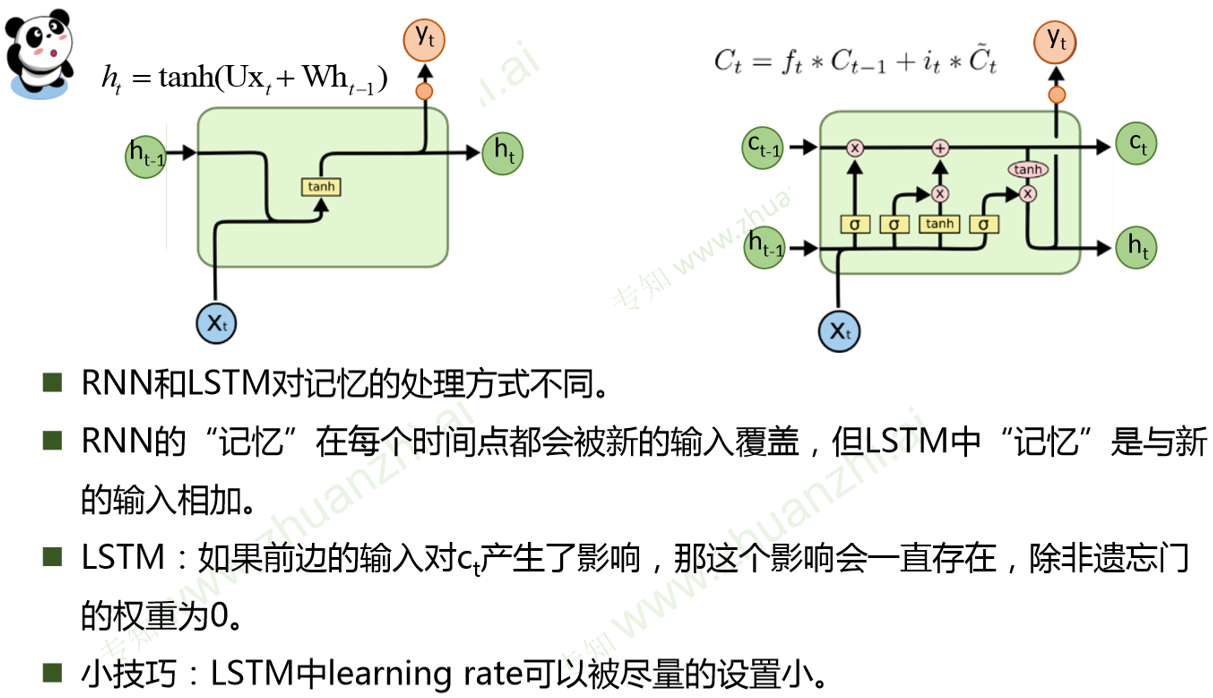
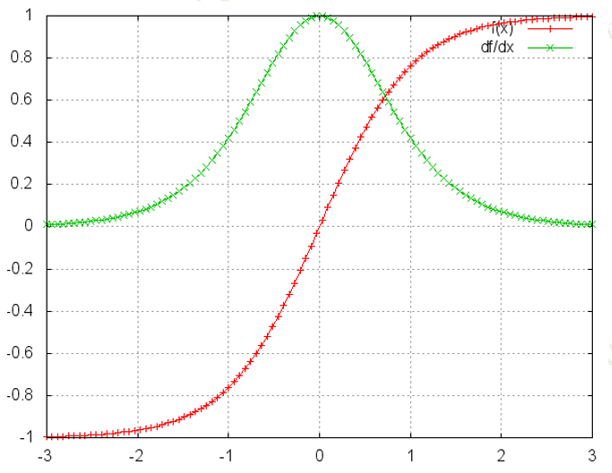
RNN记忆单元ht是累乘形式,复合函数的嵌套。
LSTM是累加形式
由于RNN是通过tanh非线性变换,所以经过较长时间后,之前的记忆会被覆盖
而LSTM是线性相加,而遗忘门ft通常接近1,所以之前的记忆会一定程度保存,解决了梯度消失问题
为了解决梯度爆炸问题,可以设置较小的learning rate
GRU门控循环单元
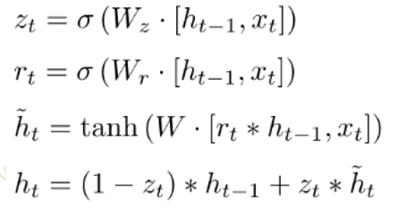
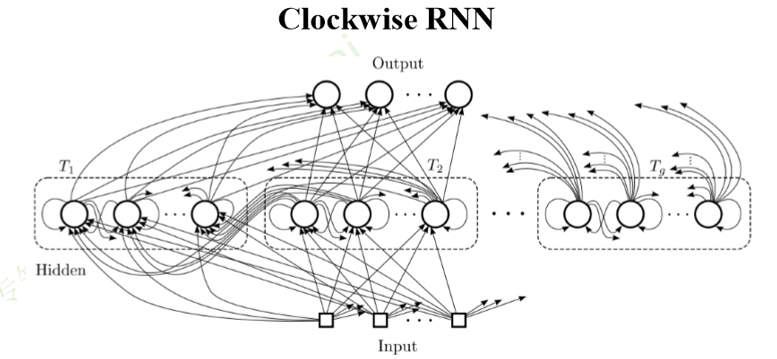
Clockwise RNN
Clockwise RNN: 普通 RNN 都是隐层从前一个时间步连接到当前时间 步。而 CW-RNN 把隐层分成很多组,每组有不同的循环周期,有的周 期是 1(和普通 RNN 一样),有的周期更长(例如从前两个时间步连 接到当前时间步,不同周期的 cell 之间也有一些连接。这样一来,距离 较远的某个依赖关系就可以通过周期较长的 cell 少数几次循环访问到, 从而网络层数不太深,更容易学到。
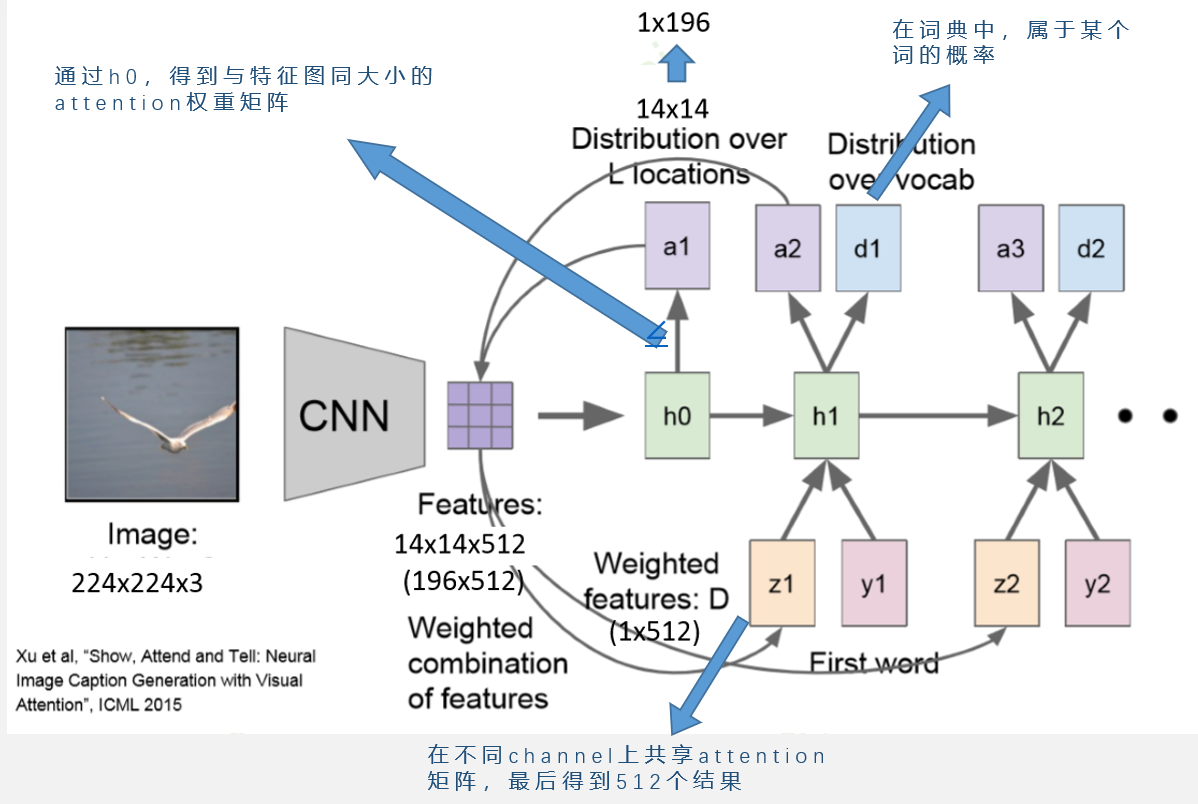
Attention
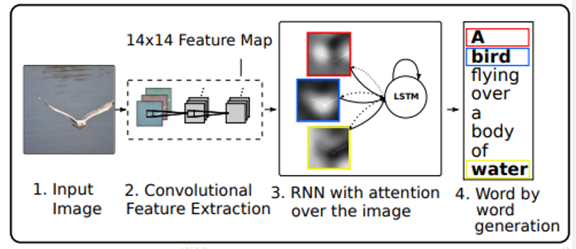

人们在进行观察图像的时候,大多是根据需求将注意力集中到图像的特定部分。而且人类会根据之前观察的图像学习到未来要观察图像注意力应该集中的位置。
评价准则
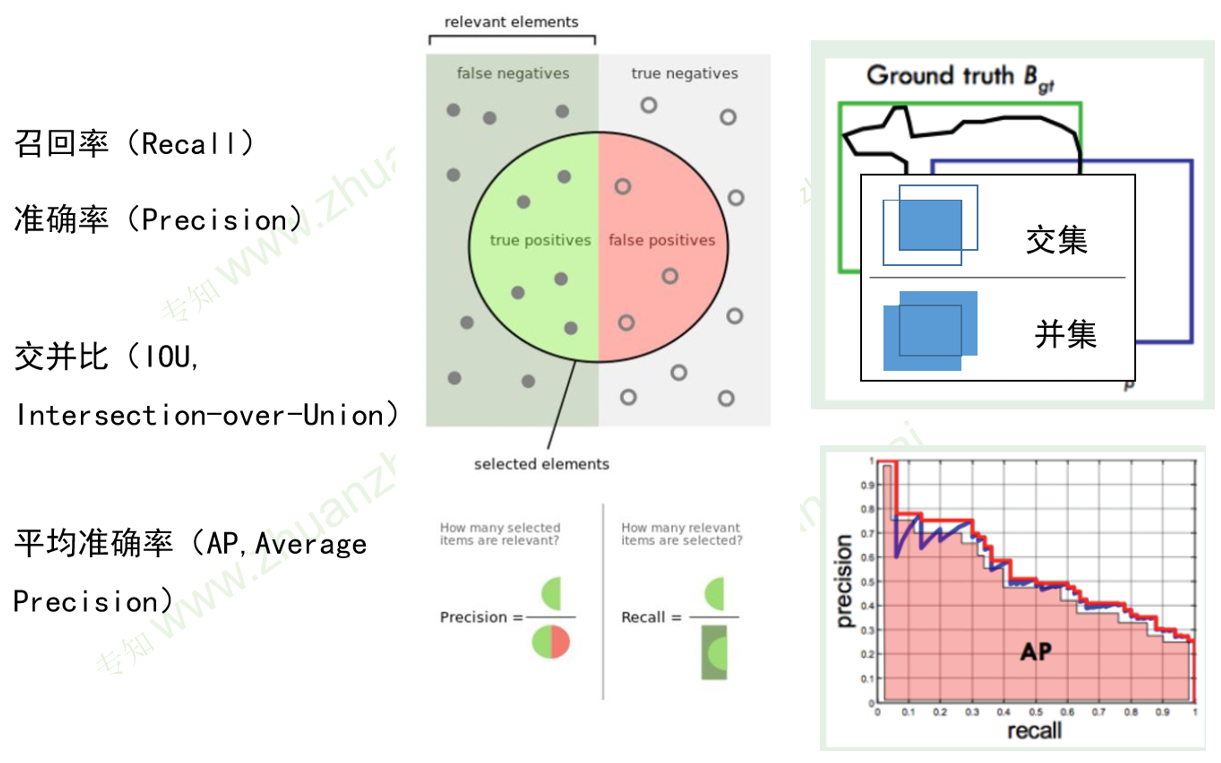
更高的召回率可能导致准确率下降,二者围成的面积称为平均准确率。
R-CNN
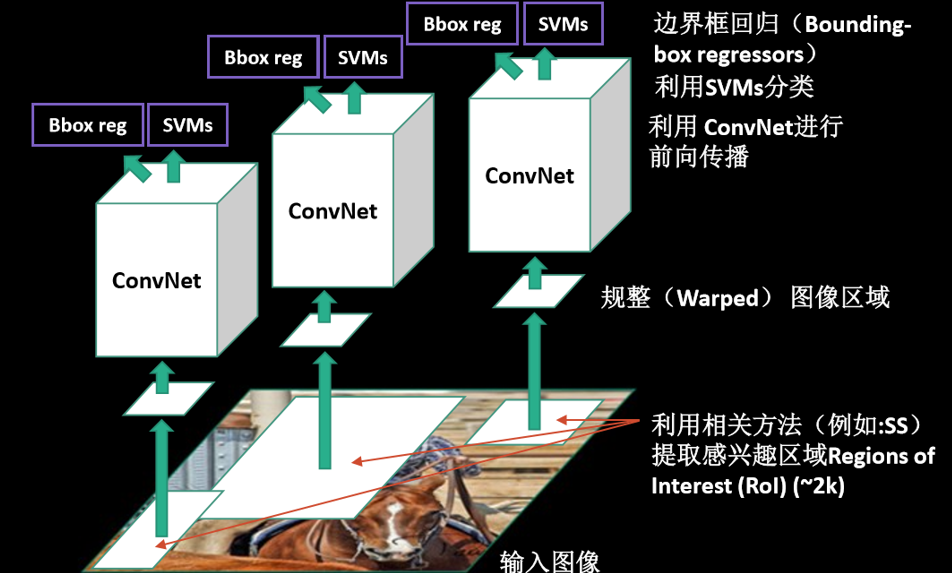
用Selective Search方法产生目标候选
由于卷积时全连接层对输入尺寸的要求,先进性规整,然后利用CNN提取特征
传入SVM进行分类
(1)CNN需要大量的训练样本(对样本质量的要求松);
(2)SVM用少量的样本就可以训练(对样本质量的要求严)。
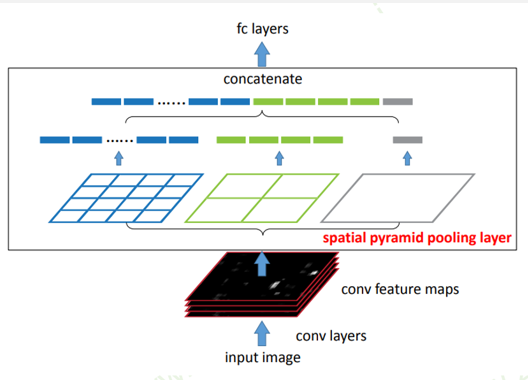
SPP-NET
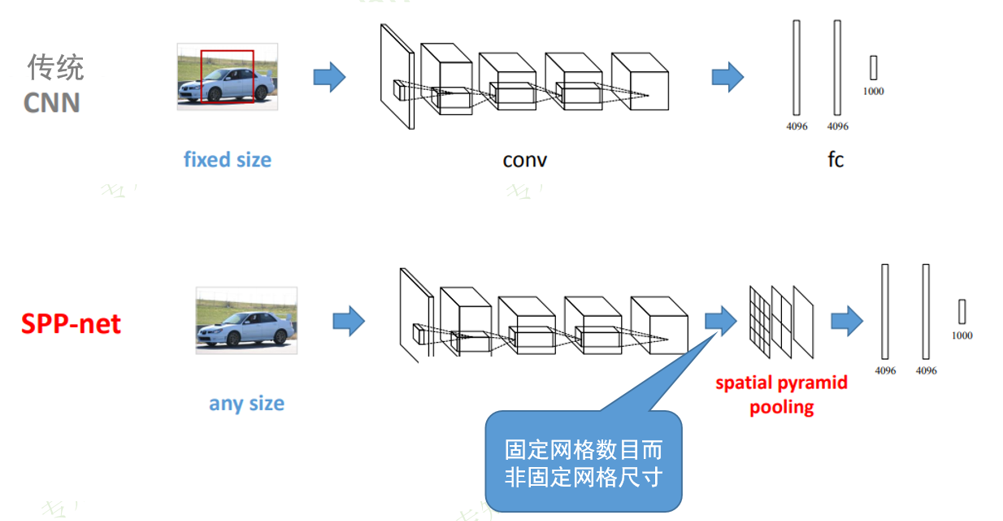
传统CNN要求输入图片尺寸一致,SPP-net在全连接层之前加入一个空间金字塔池化层
Fast-RCNN
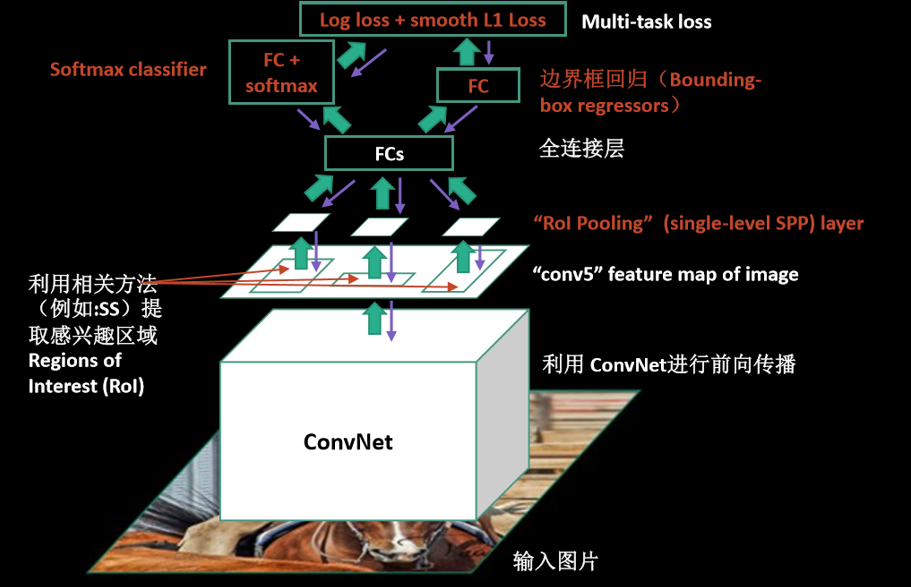

将图片的规整转化为对特征图的规整
将单独的SVM分类任务转化为CNN中的Softmax分类任务,并且将误差反向传播,进行全局的优化
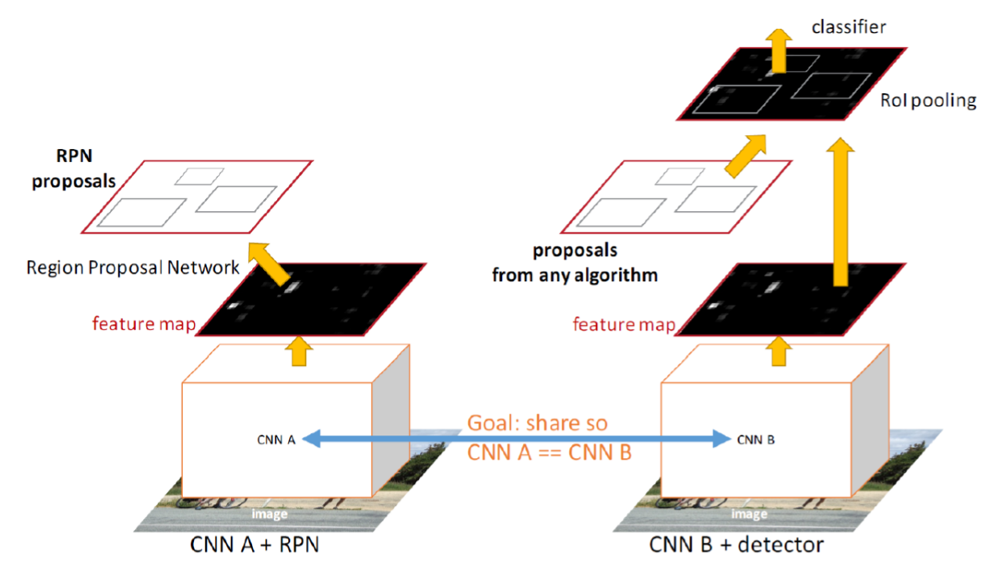
Faster RCNN没有使用ss提取方法,而是使用RPN方法,RPN插入到最后一个卷积层后,用于直接产生候选区域,不需要额外算法,RPN之后,使用ROI Poling和后续的分类器、回归器
Faster-RCNN
RoI Pooling层利用proposals从feature maps中提取proposal feature送入后续全连接和softmax网络作classification(即分类proposal到底是什么object)
Conv layers。作为一种CNN网络目标检测方法,Faster RCNN首先使用一组基础的conv+relu+pooling层提取image的feature maps。该feature maps被共享用于后续RPN层和全连接层。
Region Proposal Networks。RPN网络用于生成region proposals。该层通过softmax判断anchors属于positive或者negative,再利用bounding box regression修正anchors获得精确的proposals。
Roi Pooling。该层收集输入的feature maps和proposals,综合这些信息后提取proposal feature maps,送入后续全连接层判定目标类别。
Classification。利用proposal feature maps计算proposal的类别,同时再次bounding box regression获得检测框最终的精确位置。
RPN

RFCN
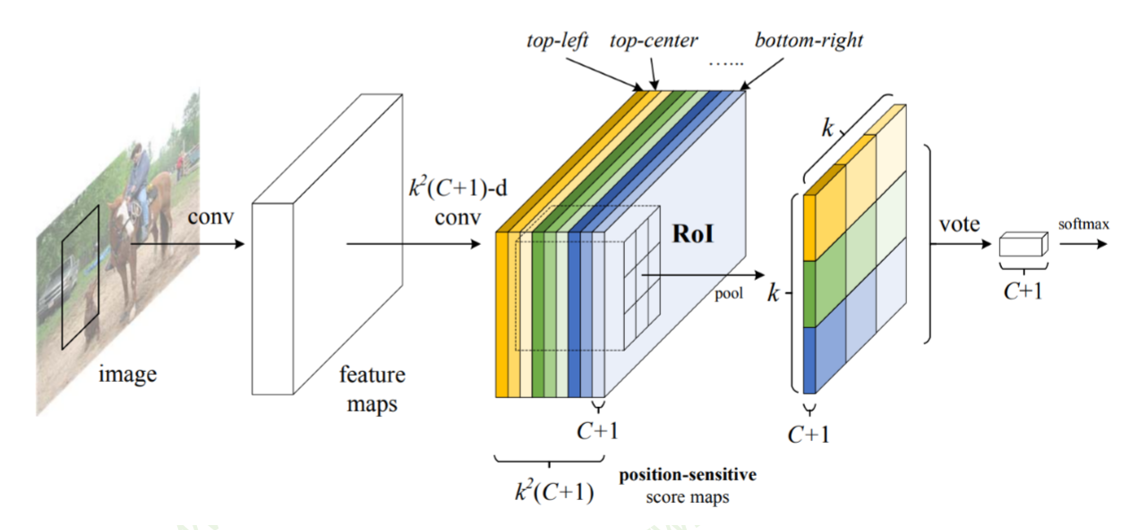
共有kk = 9个颜色,每个颜色的立体块(WH(C+1))表示的是不同位置存在目标的概率值(第一块黄色表示的是左上角位置,最后一块淡蓝色表示的是右下角位置)。共有k^2(C+1)个feature map。每个feature map,z(i,j,c)是第i+k(j-1)个立体块上的第c个map(1<= i,j <=3)。(i,j)决定了9种位置的某一种位置,假设为左上角位置(i=j=1),c决定了哪一类,假设为person类。在z(i,j,c)这个feature map上的某一个像素的位置是(x,y),像素值是value,则value表示的是原图对应的(x,y)这个位置上可能是人(c=‘person’)且是人的左上部位(i=j=1)的概率值
YOLO
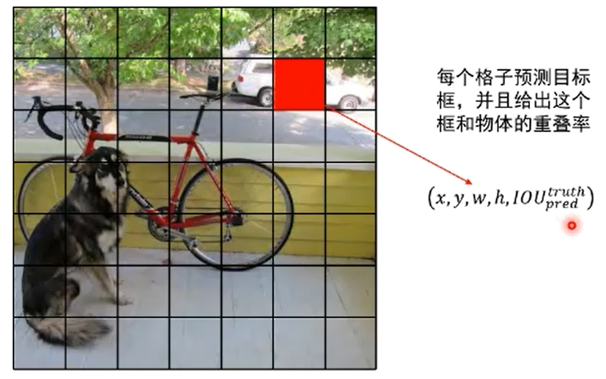
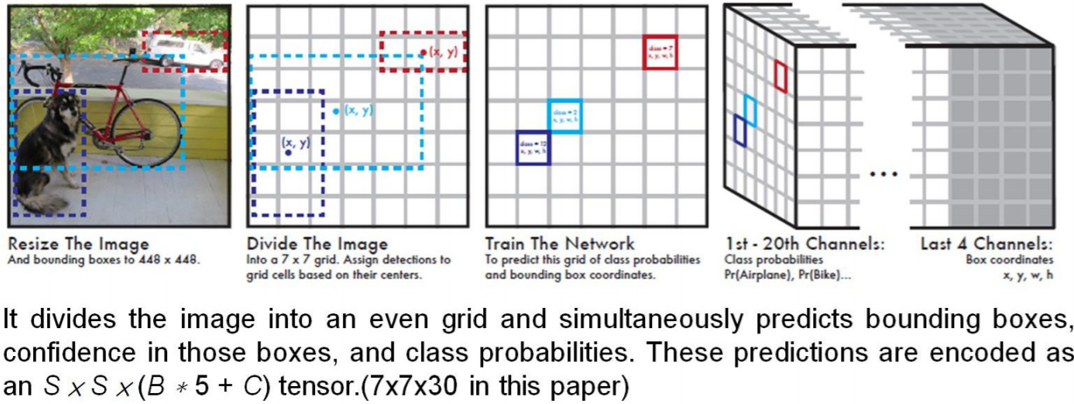
把输入图像划分为S*S个网格(S=7)。位于目标中心的网格负责检测该目标
(1) 每个网格预测B个边界框和这个边界框是物体的概率(Objectness);具体 的,每个边界框会预测出5个值:x,y,w,h和置信度Pr(Object)*IOU(truth&pred)
(2) 每个网格预测C个条件概率Pr(Classi|Object)
在测试阶段,预测每个检测框的分数:
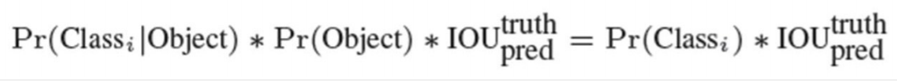
SSD
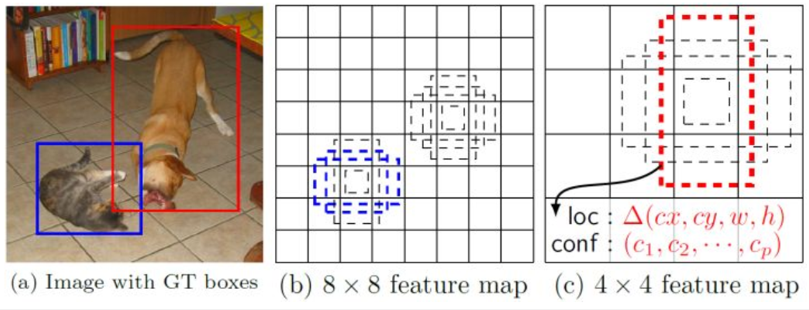
在Yolo中,每个单元预测多个边界框,但是其都是相对这个单元本身(正方块),但是真实目标的形状是多变的,Yolo需要在训练过程中自适应目标的形状。而SSD借鉴了Faster R-CNN中anchor的理念,每个单元设置尺度或者长宽比不同的先验框,预测的边界框(bounding boxes)是以这些先验框为基准的,在一定程度上减少训练难度。
对于每个单元的每个先验框,其都输出一套独立的检测值,对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度或者评分,SSD将背景也当做了一个特殊的类别,如果检测目标共有 c个类别,SSD其实需要预测 c+1 个置信度值,其中第一个置信度指的是不含目标或者属于背景的评分。
第二部分就是边界框的location,包含4个值 (cx、cy、w、h),分别表示边界框的中心坐标以及宽高。

Retina Net
由于One Stage方法背景较多,模型大量聚焦在背景中,虽然有些背景很容易分类,但由于数量巨大,导致总和的loss对检测器产生影响。
所以Retina Net通过Focal Loss使得越接近背景的样本权重越小,从而使loss主要来源于更复杂的样本,而不是简单的背景样本
