马尔可夫链
每个状态的转移只依赖于之前的n个状态。最简单的马尔可夫过程是一阶过程,即每一个状态的转移只依赖于之前的那一个状态。
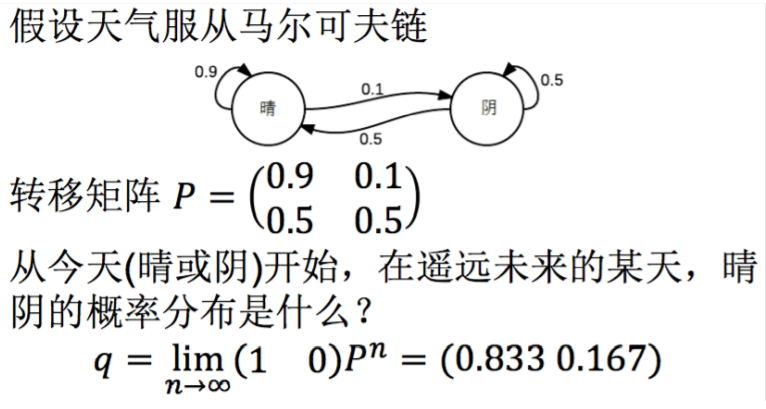
明天的概率分布为
后天的概率分布为继续乘上转移矩阵,最后概率趋于稳定,得到稳态分布。

我们为上面的一阶马尔可夫过程定义了以下三个部分:
- 状态:晴天、阴天
- 初始向量:系统在时间为0的时候状态的分布概率,如(1,0)
- 状态转移矩阵:每种状态转移的概率
所有能被这样描述的系统都是一个马尔可夫过程。
隐马尔可夫模型(HMM)
隐马尔可夫模型(Hidden Markov Model)是一种统计模型,用来描述一个含有隐含未知参数的马尔可夫过程。难点是从可观测的参数中确定该过程的隐含参数,然后利用参数做进一步分析。
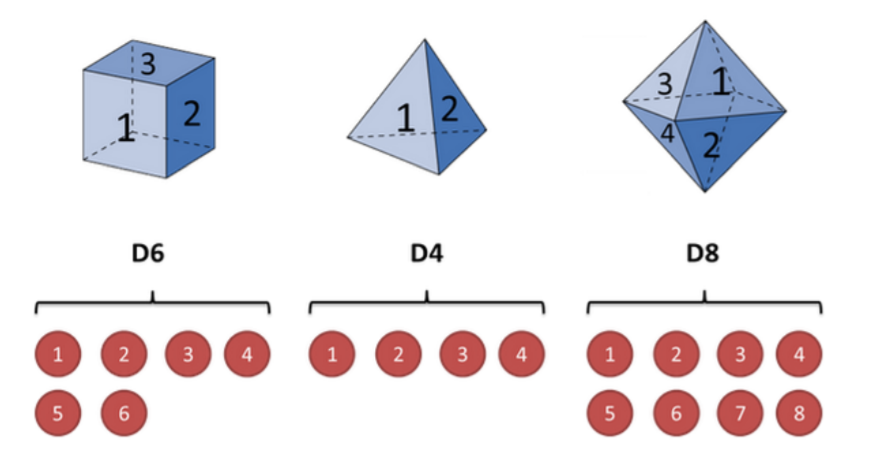
用掷骰子举例,假设有三种骰子,分别为6面、4面、8面,选中每个骰子的概率都为1/3。
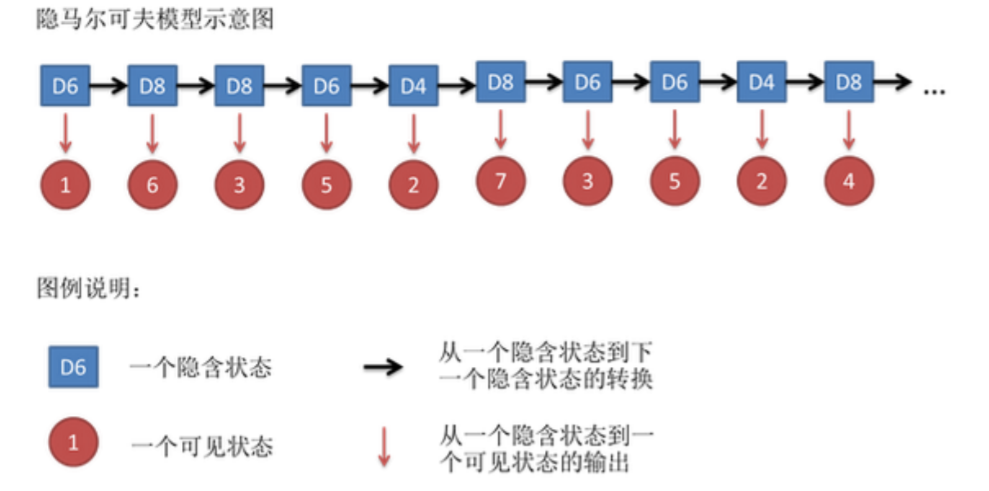
隐藏的马尔可夫链随机生成的状态序列,称为状态序列;每个状态生成一个观测,而由此产生的观测随机序列,称为观测序列。序列的每个位置又可以看作是一个时刻。
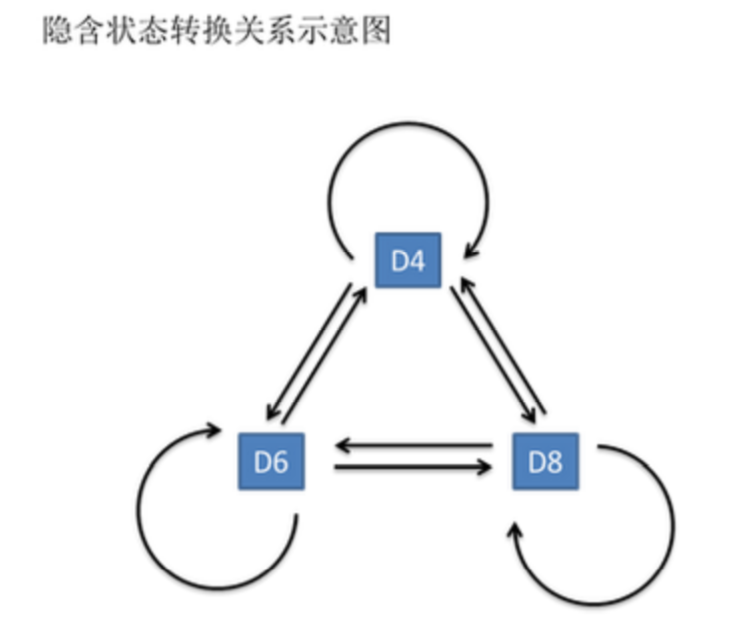
基本假设
- 齐次马尔可夫性假设,即假设隐藏的马尔可夫链在任意时刻t的状态只依赖于前一时刻的状态,与其他时刻的状态及观测无关。
- 观测独立性假设,即假设任意时刻的观测只依赖与该时刻的马尔科夫链的状态,与其他观测及状态无关。
隐马尔可夫链三大问题
隐马尔可夫模型由三个概率确定:
- 初始概率分布,即初始的隐含状态的概率分布,记为$π$;
- 状态转移概率分布,即隐含状态间的转移概率分布, 记为$A$;
- 观测概率分布,即由隐含状态生成观测状态的概率分布, 记为$B$。
以上的三个概率分布可以说就是隐马尔可夫模型的参数,而根据这三个概率,能够确定一个隐马尔可夫模型
$λ=(A,B,π)$。
而隐马尔科夫链的三个基本问题为:
- 概率计算问题。即给定模型$λ=(A,B,π)$和观测序列$O$,计算在模型$λ$下观测序列出现的最大概率$P(O|λ)$;
- 解码问题。给定模型$λ=(A,B,π)$和观测序列$O$,计算最有可能产生这个观测序列的隐含序列$X$, 即使得概率$P(X|O,λ)$最大的隐含序列$X$。
- 学习问题。即给定观测序列$O$,估计模型的参数$λ$, 使得在该参数下观测序列出现的概率最大,即$P(O|λ)$最大;
也即:
1、给定一个模型,如何计算某个特定的输出序列的概率
2、给定一个模型和某个模型的输出序列,如何找到最可能产生这种输出的状态序列
3、给定足够量的观测数据,如何估计隐马尔可夫模型的参数
假设一个隐马尔可夫过程的例子,则$(A,B,π)$如下图所示:
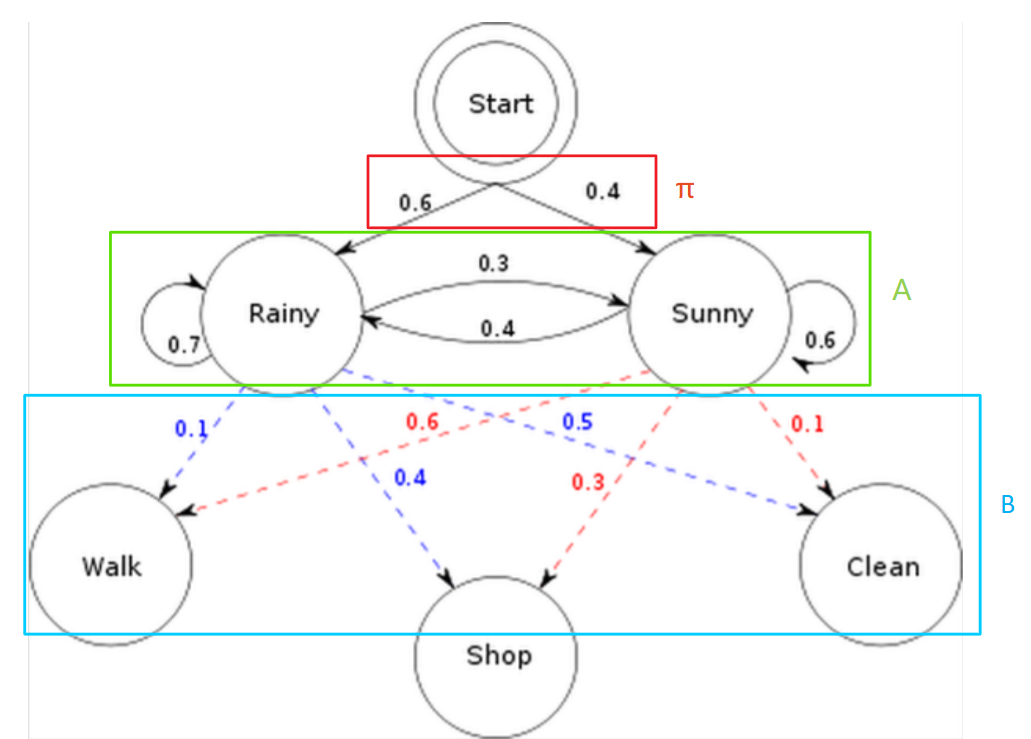
则三个问题为:
- 已知整个模型,观测到连续三天做的事情是:散步、购物、清理。那么根据模型,计算产生这些行为的概率是多少。
- 已知整个模型,同样是这三件事,猜测这三天的天气如何。
- 最复杂的问题,在只知道这三天做了这三件事的情况下,建立整个模型,给出$(A,B,π)$
隐马尔可夫链解法
- 问题一:Forward Algorithm,向前算法;或者Backward Algorithm,向后算法
- 问题二:Viterbi Algorithm,维特比算法
- 问题三:Baum-Welch Algorithm,鲍姆-韦尔奇算法
问题一
参考: 前向算法、后向算法
遍历算法
已知三天做的事情是:散步、购物、清理。三天的可能天气组合为$2^3=8$,遍历每种可能,求出概率。
- 当状态和观测节点较少时,遍历法更有效,但随着节点数增多,计算复杂度急剧增加。
前向算法

看成时间序列,按照t=1、t=2···的顺序计算。
先计算第一天散步的概率,包括$P(Walk_1,Rainy_1)和P(Walk_1,Sunny_1)$
计算第二天购物的概率:包括$P(Walk_1,Shop_2,Rainy_2)和P(walk_1,Shop_2,Sunny_2)$
分别为:
计算第三天清理的概率:包括$P(Walk_1,Shop_2,Clean_3,Rainy_3)和P(walk_1,Shop_2,Clean_3,Sunny_3)$
后向算法


计算所有后向概率$β_t$,最后通过后向概率求出观测序列概率
- 定义最后时刻T所有状态的后向概率为1,即$ β_3(S)=1、 β_3(R)=1 $
- $a_{R\rightarrow R}$表示前一天下雨的情况下,后一天也下雨的概率,$b_R(O_3=C)$表示下雨的情况下清理的概率,则第二天的后向概率:
前后向算法代码
1 | from numpy import * |
问题二
viterbi算法
参考: https://www.zhihu.com/question/20136144
参考: https://blog.csdn.net/hudashi/article/details/87875259
隐马尔科夫的预测问题就是要求图中的一条路径,使得该路径对应的概率值最大。 对应上图来讲,假设每个时刻x可能取的值为3,如果直接求的话,有3^N的组合数,底数3为篱笆网络宽度,指数N为篱笆网络的长度,计算量非常大。维特比利用动态规划的思想来求解概率最大路径(可理解为求图最短路径),使得复杂度正比于序列长度,复杂度为O(N⋅D⋅D), N为长度,D为宽度,从而很好地解决了问题的求解。
1、如果概率最大的路径经过篱笆网络的某点,则从开始点到该点的子路径也一定是从开始到该点路径中概率最大的。
2、假定第i时刻有k个状态,从开始到i时刻的k个状态有k条最短路径,而最终的最短路径必然经过其中的一条。
3、根据上述性质,在计算第i+1状态的最短路径时,只需要考虑从开始到当前的k个状态值的最短路径和当前状态值到第i+1状态值的最短路径即可,如求t=3时的最短路径,等于求t=2时的所有状态结点x2i的最短路径加上t=2到t=3的各节点的最短路径。
算法流程
定义t时刻状态为i的所有单个路径 (i1, i2, …, it) 中最大概率值(最短路径)为
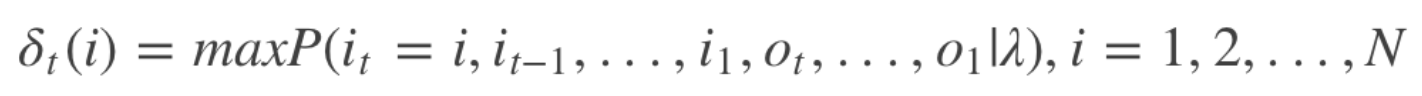
其中,$i_t$表示最短路径,得到变量的递推公式:
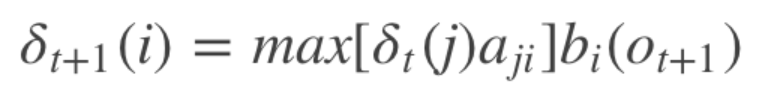
其中i = 1, 2, …, N; t = 1, 2, … , T-1,定义在时刻t状态为i的所有单个路径 (i1, i2, …, it, i) 中概率最大的路径的第t-1个结点为:
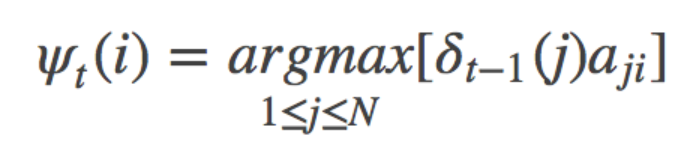
初始化参数
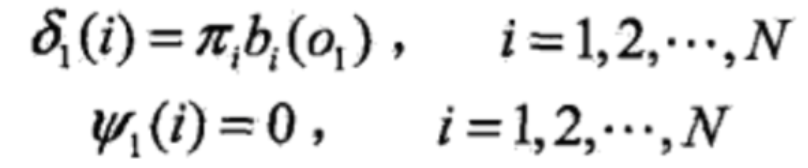
开始递推
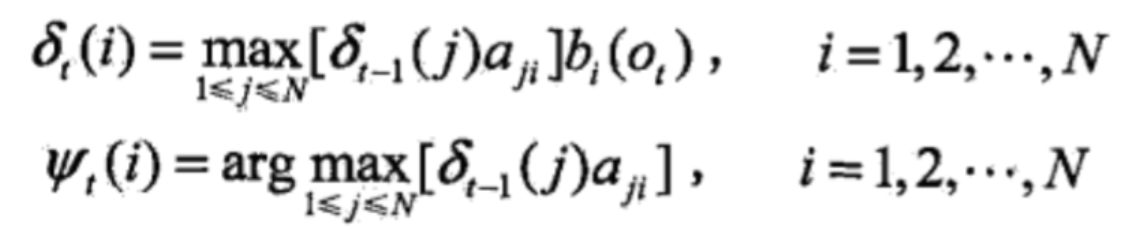
- 最后的终止状态(T状态)计算:
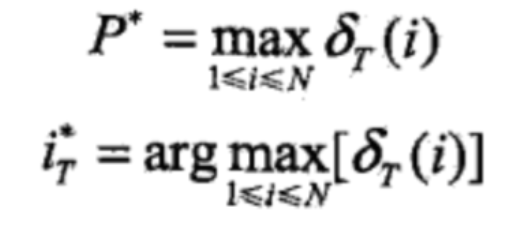
- 最优路径的回溯,对t=T-1, T-2,…, 1
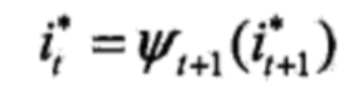
则最优路径为:
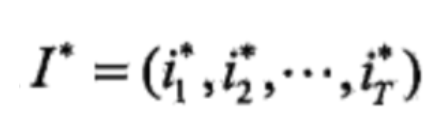
例子
- 计算t=1时刻Walk的概率
$\psi_1(R)=0、\psi_1(S)=0$
- 计算t=2时刻Shop发生的概率
$\psi_2(R)=Rainy、\psi_2(S)=Rainy$
- 计算t=3时刻Clean的概率
$\psi_3(R)=Rainy、\psi_3(S)=Rainy$
$i^_T=Sunny,i^_2=\psi_3(Sunny)=Rainy,i^*_1=\psi_2(Rainy)=Rainy$
$I^*=(Rainy,Rainy,Sunny)$
问题三
先导:EM算法
Baum-Welch算法
由于只知道观测值,所以算法没有全局最优解,只能找到局部最优解。
参考: https://blog.csdn.net/u014688145/article/details/53046765