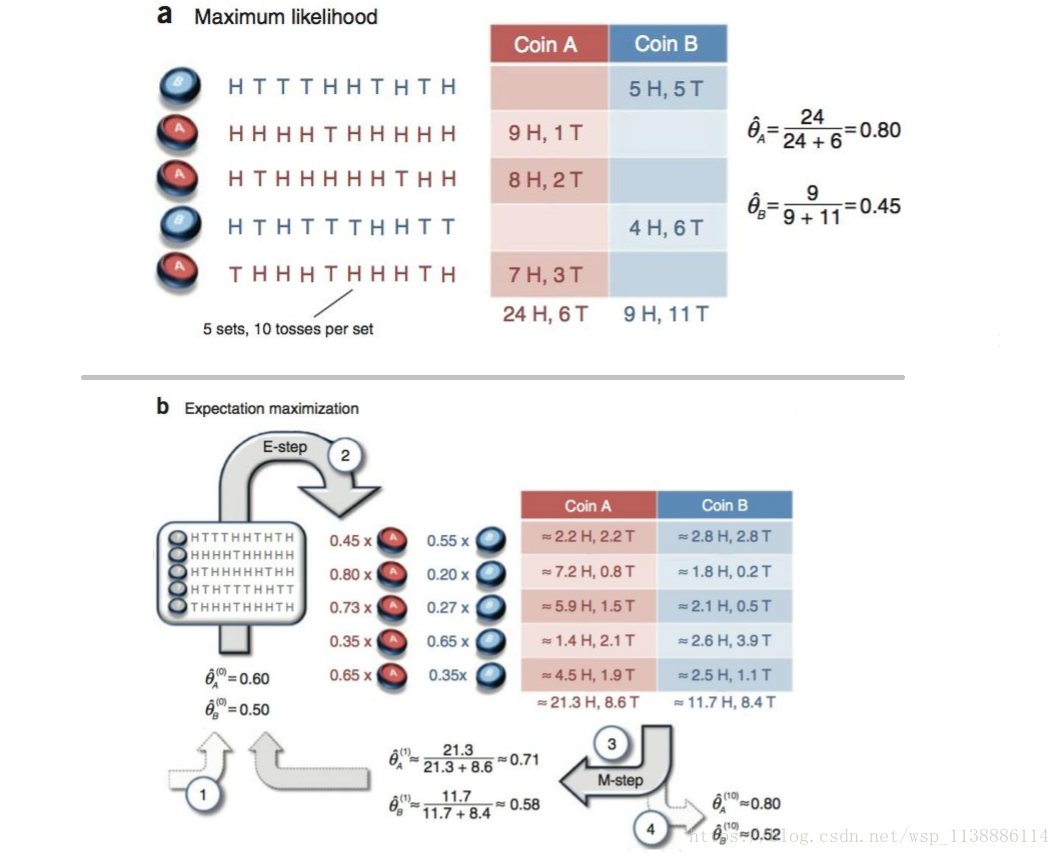
极大似然估计
参考: https://www.zhihu.com/question/24124998
极大似然是对概率模型参数学习优化目标的一种定义 。 就是利用已知的样本结果信息,反推最具有可能(最大概率)导致这些样本结果出现的模型参数值 。
对于离散型的随机变量:
![[公式]](/2020/08/05/极大似然与EM算法/equation.svg)
如果是一个连续型的随机变量 :
![[公式]](/2020/08/05/极大似然与EM算法/equation-1596608492814.svg)
想对$L(\theta)$求最值,为了便于求导,两边取对数,有:
![[公式]](/2020/08/05/极大似然与EM算法/equation-1596608606746.svg)
如果方程有唯一解,且是极大值点,那么我们就求得了极大似然估计值。
例子1:抛硬币

例子2:单参数

例子3:多参数


总体方差的极大似然估计值的分母是 ![[公式]](/2020/08/05/极大似然与EM算法/equation-1596609741462.svg) 而不是
而不是 ![[公式]](/2020/08/05/极大似然与EM算法/equation-1596609741458.svg) ,因此他不是一个无偏估计量。但是可以说他是渐近无偏的
,因此他不是一个无偏估计量。但是可以说他是渐近无偏的
EM算法
参考: https://blog.csdn.net/wsp_1138886114/article/details/81002550
参考: https://www.cnblogs.com/jerrylead/archive/2011/04/06/2006936.html
EM算法是用于求解极大似然估计的一种迭代逼近的算法 。
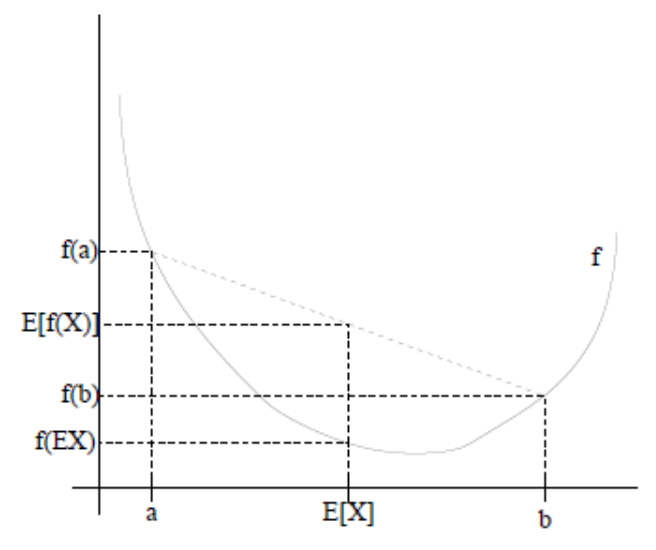
Jensen不等式
 、
、
设f是定义域为实数的函数,如果对于所有的实数x, $f^{‘’}(x)\geqslant 0$ 那么f是凸函数,如果$f^{‘’}(x)> 0$ 那么f是严格凸函数。
jensen不等式: 如果f是凸函数,X是随机变量,那么 $E[f(x)]\geqslant f[E(x)]$,特别的,如果f是严格凸函数,那么当且仅当$p(x=E[x])=1$时(X为常量),取得 $E[f(x)]= f[E(x)]$
lazy Statistician规则
设 y 是随机变量 x 的函数,$y=g(x)(g是连续函数)$,那么:
(1) x 是离散随机变量,分布为$p(x=x_k)=p_k,k∈N∗$,若$∑^∞_{k=1} g(x) p_k$绝对收敛,则
(2) x 是连续随机变量,分布概率为$f(x)$,若$∫^∞_{−∞}g(x)f(x)dx$ 绝对收敛,则
EM公式推导
假设我们有一个样本集${x(1),…,x(m)}$,包含m个独立的样本。但每个样本i对应的类别z(i)是未知的,也即隐含变量。故我们需要估计概率模型$p(x,z)$的参数$θ$,但是由于里面包含隐含变量z,所以很难用最大似然求解。
思路是既然不能直接最大化$L(\theta)$,我们可以不断地建立$L(\theta)$的下界(E步),然后优化下界,得到新参数$\theta$(M步)
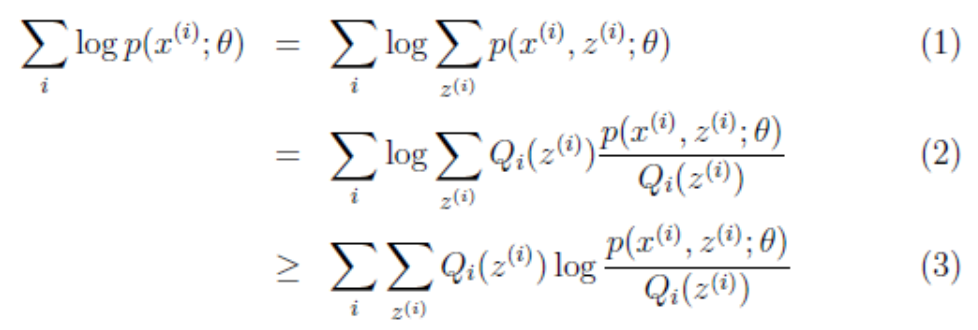
(1)对每个样例的每个可能类别z求联合分布概率和,由于”和的对数“求导困难( log(f1(x)+ f2(x)+ f3(x)+··· 复合函数求导),因此进行化简。 对于每一个样例i,让$Q_t$ 表示该样例隐含变量z的某种分布, $Q_t$满足的条件是$\sum_zQ_i(z)=1,Q_i(z)\geqslant 0$,如果z是连续的,那么$Q_t$是概率密度函数,将求和号换成积分号。
对于公式(3),由于$log(x)$是凹函数,且
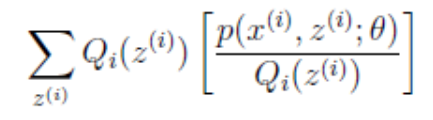
是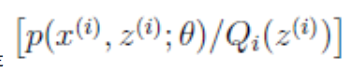 的期望,根据Jensen不等式,对于凹函数有:
的期望,根据Jensen不等式,对于凹函数有:
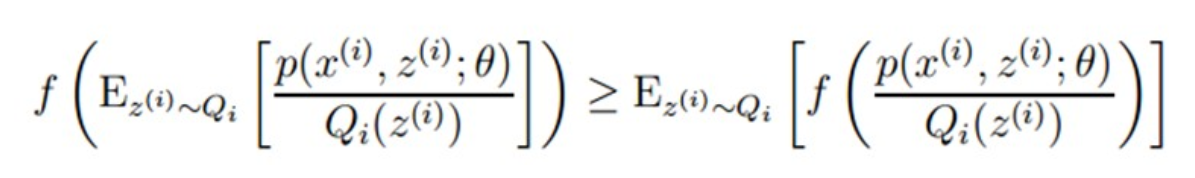
这个过程可以看作对$L(\theta)$求下界,固定$\theta$,那么$L(\theta)$的值就取决于$Q_i(z^{(i)})$和$p(x^{(i)},z^{(i)};\theta)$ 。我们可以通过调整这两个概率使下界不断上升,以逼近$L(θ)$的真实值,那么什么时候算是调整好了呢?当不等式变成等式时,说明我们调整后的概率都能够等价于$L(θ)$了。按照这个思路,我们要找到等式成立的条件。根据Jensen不等式,要想让等式成立,需要让随机变量变成常数值,这里得到
C为常数,不依赖于$z^{(i)}$,由于$\sum_zQ_i(z)=1$,分子分母同时求和(认为每个比值都是C,这样分子分母同时求和结果不变),于是得到$\sum_z p(x^{(i)},z^{(i)};\theta)=C$,则
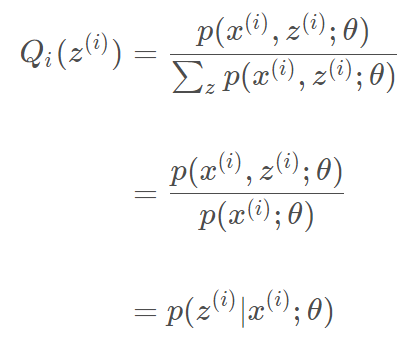
之前说$L(\theta)$的值取决于$Q_i(z^{(i)})$和$p(x^{(i)},z^{(i)};\theta)$,但我们为了取到等号,让两者的比值等于常数,也就是说$Q_i(z^{(i)})$和$p(x^{(i)},z^{(i)};\theta)$其实是同比例变化的。
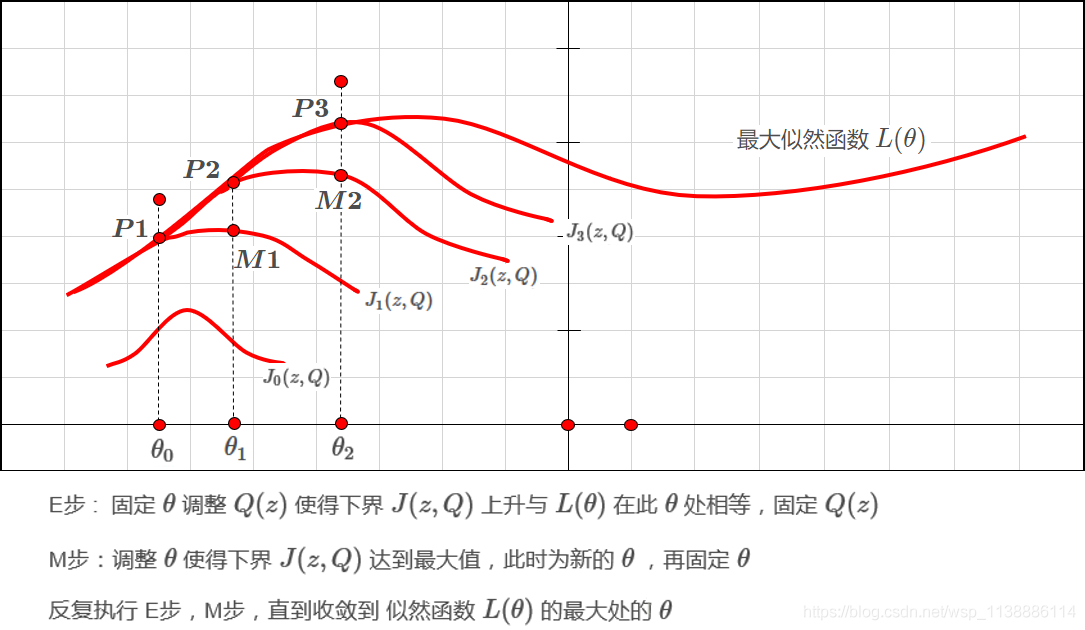
至此,我们推出了在固定参数$θ$后,使下界拉升的$Q(z)$的计算公式就是后验概率,解决了$Q(z)$如何选择的问题。这一步就是E步,建立$L(θ)$的下界。接下来的M步,就是在给定$Q(z)$后,调整$θ$,去极大化$L(θ)$的下界J(在固定$Q(z)$后,下界还可以调整的更大)。那么一般的EM算法的步骤如下:
- 在 E-step:固定$\theta$,找到对于当前参数 $θ$使不等式成立的 $Q$分布,使得下界$J(Z,Q)$不断上升,直到与$L(θ)$在$θ$点重合。
- 在 M-step:固定$Q(z)$,对似然函数下界进行极大似然估计,找到$J(Z,θ)$的极大值,得到新的参数
形式化表示为:
- E-step $Q_i(z^{(i)})=p(z^{(i)}∣x^{(i)};θ) $
- M-step $θ=\arg \max_\theta{∑^n_{i=1}∑_{z^{(i)}}Qi(z^{(i)})log\frac {p(x^{(i)}),z^{(i)};θ)}{Qi(z^{(i)})}} $
由于$L(\theta)$会单调增加。因此EM算法收敛。
证明:收敛证明
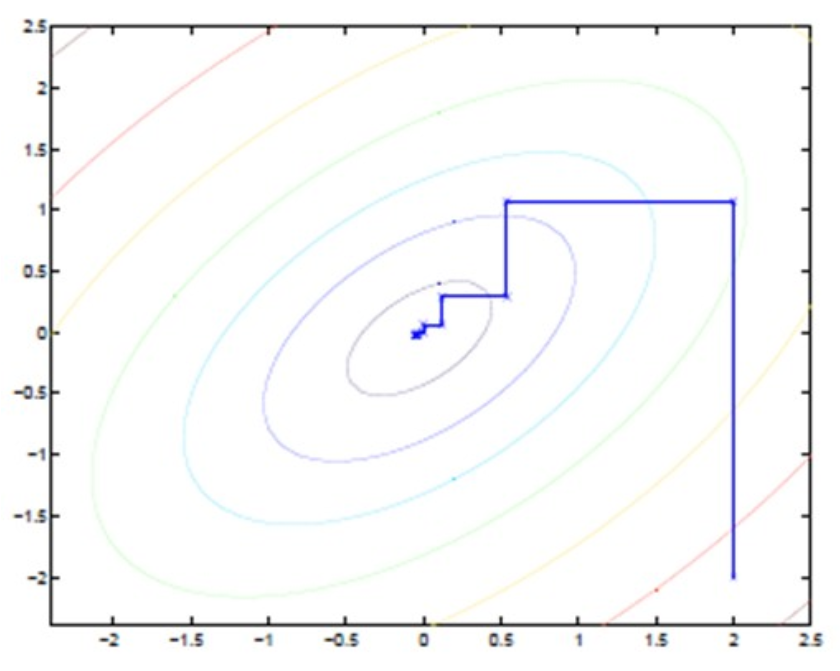
直线式迭代优化
每一步都会向最优值前进一步,而且前进路线是平行于坐标轴的,因为每一步只优化一个变量。这犹如在x-y坐标系中找一个曲线的极值,然而曲线函数不能直接求导,因此梯度下降方法不适用。
但固定一个变量后,另外一个可以通过求导得到,因此可以使用坐标上升法,一次固定一个变量,对另外的求极值,最后逐步逼近极值。
对应到EM上, E步:固定θ,优化Q;M步:固定Q,优化θ;交替将极值推向最大。
EM算法实例
● 假设现在有两枚硬币1和2,随机抛掷后正面朝上概率分别为$P_1、P_2$。为了估计这两个概率,每次取一枚硬币,连掷5下,记录下结果,如下
| 表一(实验数据) | 表二(测试数据) | |||||
|---|---|---|---|---|---|---|
| 硬币 | 结果 | 统计 | 硬币 | 结果 | 统计 | |
| 1 | 正正反正反 | 3正-2反 | UnKnow | 正正反正反 | 3正-2反 | |
| 2 | 反反正正反 | 2正-3反 | UnKnow | 反反正正反 | 2正-3反 | |
| 1 | 正反反反反 | 1正-4反 | UnKnow | 正反反反反 | 1正-4反 | |
| 2 | 正反反正正 | 3正-2反 | UnKnow | 正反反正正 | 3正-2反 | |
| 1 | 反正正反反 | 2正-3反 | UnKnow | 反正正反反 | 2正-3反 |
表一:可以很容易地估计出P1和P2,如下:
P1 = (3+1+2)/ 15 = 0.4
P2= (2+3)/10 = 0.5
● 现在我们抹去每轮投掷时使用的硬币标记,如上右表(表二(测试数据))。
目标没变,还是估计P1和P2:
此时多了一个隐变量z,可以把它认为是一个5维的向量(z1,z2,z3,z4,z5),
代表每次投掷时所使用的硬币,比如z1,就代表第一轮投掷时使用的硬币是1还是2。
但是,这个变量z不知道,就无法去估计P1和P2。
我们可以先随机初始化一个P1和P2,用它来估计z,然后基于z,还是按照最大似然概率法则去估计新的P1和P2
当与我们初始化的P1和P2一样时,说明是P1和P2很有可能就是真实的值。这里面包含了两个交互的最大似然估计。(参数$\theta$在这里就是需要求解的P1、P2)
计算过程
当假设P1 = 0.2,P2 = 0.8时: (看看第一轮抛掷最可能是哪个硬币。)
如果是硬币1,得出3正2反的概率为:
0.2×0.2×0.2×0.8×0.8= 0.00512
如果是硬币2,得出3正2反的概率为:
0.8×0.8×0.8×0.2×0.2=0.03087
依次求出其他4轮中的相应概率。(如:表三)
| 按照最大似然法则:(表三) | 轮数 | 若是硬币1 | 若是硬币2 |
|---|---|---|---|
| 第1轮中最有可能的是硬币2 | 1 | 0.00512 | 0.03087 |
| 第2轮中最有可能的是硬币1 | 2 | 0.02048 | 0.01323 |
| 第3轮中最有可能的是硬币1 | 3 | 0.08192 | 0.00567 |
| 第4轮中最有可能的是硬币2 | 4 | 0.00512 | 0.02048 |
| 第5轮中最有可能的是硬币1 | 5 | 0.02048 | 0.01323 |
我们就把上面的值作为z的估计值。
然后按照最大似然概率法则来估计新的P1和P2。(由表三,查到 表二的正反数据计算P值)
P1 = (2+1+2)/15 = 0.33
P2=(3+3)/10 = 0.6
将算的的P1P2反复迭代:
设想我们知道每轮抛掷时的硬币就是如标示的那样,那么,P1和P2的最大似然估计就是0.4和0.5 (下文中将这两个值称为P1和P2的真实值)。那么对比下我们初始化的P1和P2和新估计出的P1和P2:
| 初始化P1 | 估计出P1 | 真实的P1 | 初始化P2 | 估计出P2 | 真实的P2 | |
|---|---|---|---|---|---|---|
| 0.2 | 0.33 | 0.4 | 0.8 | 0.6 | 0.5 |
优化
新估计出的 P1和P2 一定会更接近真实的 P1和P2
迭代不一定会收敛到真实的P1和P2。取决于P1和P2的初始化值。
用期望来简化运算
再次利用表三:我们可以算出每轮抛掷中使用硬币1或者使用硬币2的概率。
比如第1轮,使用硬币1的概率是:0.00512/(0.00512+0.03087)=0.14
使用硬币2的概率是:1-0.14=0.86
我们按照期望最大似然概率的法则来估计新的P1和P2:
以P1估计为例,(表二)第1轮的3正2反相当于
0.14*3=0.42正
0.14*2=0.28反
依次算出其他四轮,表四如下:new_P1=4.22/(4.22+7.98)=0.35
| 轮数 | 正面 | 反面 |
|---|---|---|
| 1 | 0.42 | 0.28 |
| 2 | 1.22 | 1.83 |
| 3 | 0.94 | 3.76 |
| 4 | 0.42 | 0.28 |
| 5 | 1.22 | 1.83 |
| 总计 | 4.22 | 7.98 |
可以看到,改变了z值的估计方法后,新估计出的P1要更加接近0.4。原因就是我们使用了所有抛掷的数据,而不是之前只使用了部分的数据。我们根据E步中求出的z的概率分布,依据最大似然概率法则去估计P1和P2,被称作M步。