目标检测二
R-CNN
论文: 《Rich feature hierarchies for accurate oject detection and semantic segmentation》
项目地址:https://github.com/rbgirshick/rcnn
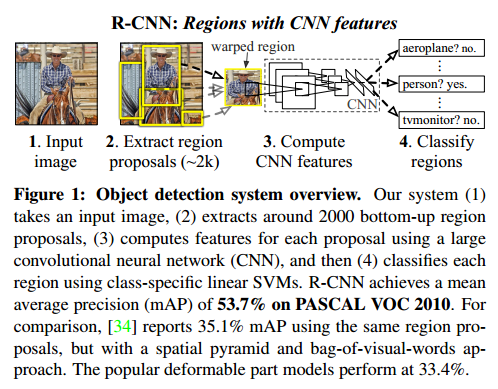
R-CNN概括起来就是selective search+CNN+L-SVM的检测器
- 用selective search代替传统的滑动窗口,提取出2k个候选region proposal
- 对于每个region,用摘掉了最后一层softmax层的AlexNet来提取特征
- 训练出来K个L-SVM作为分类器(每个目标类一个SVM分类器,K目标类个数),使用AlexNet提取出来的特征作为输出,得到每个region属于某一类的得分
- 最后对每个类别用NMS(non-maximum-suppression)来舍弃掉一部分region,得到detection的结果(对得到的结果做针对boundingbox回归,用来修正预测的boundingbox的位置)
迁移学习
采用在 ImageNet ( ImageNet ILSVC 2012 , 一千万图像,1000类 )上已经训练好的模型,然后在 PASCAL VOC ( PASCAL VOC 2007 , 一万图像,20类 )数据集上进行 fine-tune。
因为 ImageNet 的图像高达几百万张,利用卷积神经网络充分学习浅层的特征,然后在小规模数据集做规模化训练,从而可以达到好的效果。 这里在 ImageNet 上训练的是模型识别物体类型的能力,而不是预测 bbox 位置的能力
特征提取
R-CNN 抽取了一个 4096 维的特征向量,采用的是 Alexnet,基于 Caffe 进行代码开发,之后送入4096->1000的全连接层进行分类,学习率0.01。
需要注意的是 Alextnet 的输入图像大小是 227x227。
而通过 Selective Search 产生的候选区域大小不一,为了与 Alexnet 兼容,R-CNN 采用了非常暴力的手段,那就是无视候选区域的大小和形状,统一变换到 227*227 的尺寸。
有一个细节,在对 Region 进行变换的时候,首先对这些区域进行膨胀处理,在其 box 周围附加了 p 个像素,也就是人为添加了边框,在这里 p=16。
调优训练
同样使用上述网络,最后一层换成4096->21的全连接网络。
学习率0.001,每一个batch包含32个正样本(属于20类)和96个背景(主要由于正样本过少)。
使用PASCAL VOC 2007的训练集,输入一张图片,输出21维的类别标号,表示20类+背景。
考察一个候选框和当前图像上所有标定框重叠面积最大的一个。如果重叠比例大于0.5,则认为此候选框为此标定的类别;否则认为此候选框为背景。
分类器
对每一类目标,使用一个线性SVM二类分类器进行判别。输入为深度网络输出的4096维特征,输出是否属于此类。
由于负样本很多,使用hard negative mining方法。
正样本 :本类的真值标定框。
负样本 :考察每一个候选框,如果和本类所有标定框的重叠都小于0.3,认定其为负样本
bbox回归
输入为深度网络pool5层的4096维特征,输出为xy方向的缩放和平移。 训练样本判定为本类的候选框中,和真值重叠面积大于0.6的候选框。
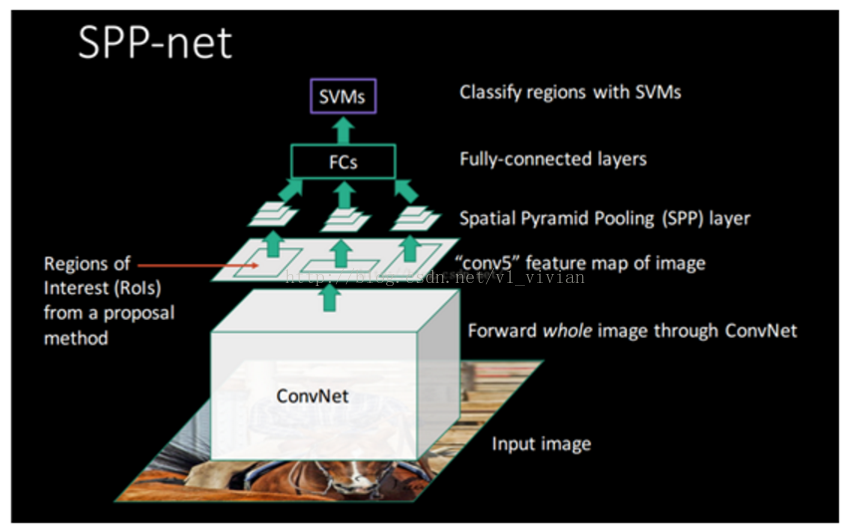
SPP-Net
论文:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
消除了CNN对于图像输入尺寸的限制, SPP-net结构能够产生固定大小的表示(fixed-length representation),而不关心输入图像的尺寸或比例。金字塔池化对物体形变很鲁棒(robust to object deformations)。 由于以上优点,SPP-net可普遍改进各种基于CNN的图像分类方法。
SPP-net在目标检测上也表现突出。用SPP-net,我们只需要从整张图片计算一次特征图(feature map),然后对任意尺寸的区域(子图像)进行特征池化,以产生一个固定尺寸的表示(representation)用于训练检测器(detectors)。 这个方法避免了反复计算卷积特征。在处理测试图像时,我们的方法在VOC2007数据集上,达到相同或更好的性能情况下,比R-CNN方法快24-102X倍。
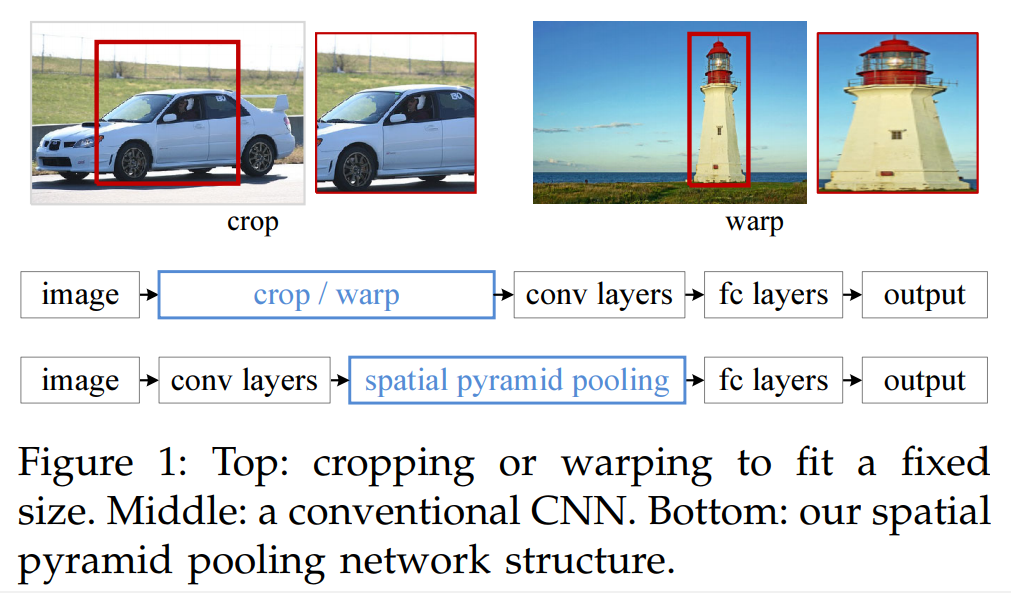
为了解决剪裁带来的信息丢失和变形导致的信息扭曲,采用空间金字塔池化( spatial pyramid pooling,SPP)层,移除对网络固定尺寸的限制(通常将其放在卷积后,FC层之前)。
SPP原理
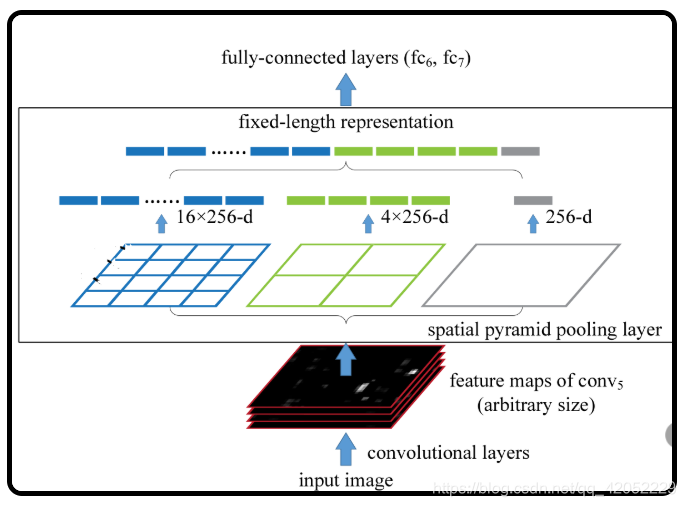
三种颜色的网格,是将从conv5得到的特征分别映射成16、4、1份,16X256中的256表示的是channel,即SPP对每一层都分成16份(不一定是等比分)。将特征映射后进行最大池化。
通过SPP,对任意的输入可以得到固定的21*256大小的输出,21指的是20个类别加上1个背景。
公式

因此,当输出的尺寸为224224时,conv5后得到的特征图大小为13\13,设为a,第一个映射为4*4,设为n。
如果想要运算后得到的大小也为n。那么令: $windows_size=[a/n]$ 向上取整 , $stride_size=[a/n]$向下取整。
一般情况下这时有:$ans = (a-n)/(a/n)+1=n$
但如果对于输入:(7,11),金字塔bins=(4,4),这时K=(2,3),Stride=(1,2),结果为(6,5),并不是(4,4)
修订公式后:

代码
1 | import math |
多尺度训练
除此之外, 训练阶段,图像可以有各种尺寸和缩放尺度。使用各种尺寸的图像进行训练,可以提高缩放不变性,以及减少过拟合。基于此的多尺度训练方法: 每个epoch,我们针对一个给定的输入尺寸进行网络训练,然后在下一个epoch,再切换到另一个尺寸。实验表明,这种多尺度训练和传统的单一尺度训练一样可以收敛,并且能达到更好的测试精度。
多尺寸训练的主要目的是在保证已经充分利用现在被较好优化的固定尺寸网络实现的同时,模拟不同的输入尺寸。
R-CNN vs SPP-Net
R-CNN
- 首先通过选择性搜索,对待检测的图片进行搜索出~2000个候选窗口。
- 把这2k个候选窗口的图片都缩放到227*227,然后分别输入CNN中,每个proposal提取出一个特征向量,也就是说利用CNN对每个proposal进行提取特征向量。
- 把上面每个候选窗口的对应特征向量,利用SVM算法进行分类识别。
SPP-Net
- 首先通过选择性搜索,对待检测的图片进行搜索出2000个候选窗口。这一步和R-CNN一样。
- 特征提取阶段。这一步就是和R-CNN最大的区别了,这一步骤的具体操作如下:把整张待检测的图片,输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。而R-CNN输入的是每个候选框,然后在进入CNN,因为SPP-Net只需要一次对整张图片进行特征提取,速度会大大提升。
- 最后一步也是和R-CNN一样,采用SVM算法进行特征向量分类识别。
用于目标检测
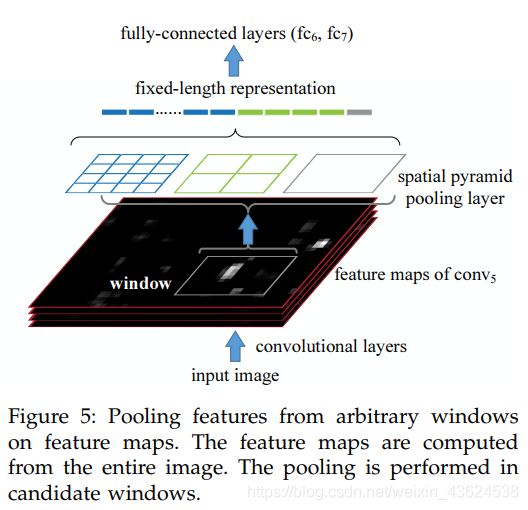
我们将SPP-net应用于物体检测。只在整张图像上抽取一次特征。然后在每个特征图的候选窗口上应用空间金字塔池化,形成这个窗口的一个固定长度表示。因为只应用一次卷积网络,这种方法快得多。
SPP-net从特征图中直接抽取特征,而R-CNN则要从图像区域抽取。之前的一些工作中,可变性部件模型(Deformable Part Model, DPM)从HOG特征图的窗口中抽取图像,选择性搜索方法从SIFT编码后的特征图的窗口中抽取特征。Overfeat也是从卷积特征图中抽取特征,但需要预定义的窗口尺寸。作为对比,我们的特征抽取可以在任意尺寸的深度卷积特征图窗口上。
我们使用选择性搜索[20]的“fast”模式对每张图片产生2000个候选窗口。然后缩放图像以满足min(w;h) = s,并且从整张图像中抽取特征图。我们暂时使用ZF-5的SPP-net 模型(单一尺寸训练)。在每个候选窗口,我们使用一个4级空间金字塔(1×1, 2×2, 3×3, 6×6, 总共50块)。每个窗口将产生一个12800(256×50)维的表示。这些表示传递给网络的全连接层。然后我们针对每个分类训练一个二分线性SVM分类器。
将我们想要的proposal映射到特征图之上,从而进行SPP 。 原图中的proposal,经过多层卷积之后,位置还是相对于原图不变的。

对于映射关系,论文中给出了一个公式:
假设(x’,y’)表示特征图上的坐标点,坐标点(x,y)表示原输入图片上的点,那么它们之间有如下转换关系,这种映射关心与网络结构有关:
反过来,我们希望通过(x,y)坐标求解(x’,y’),那么计算公式如下:
其中S就是CNN中所有的strides的乘积,包含了池化、卷积的stride。
比如,对于下图的集中网络结构,S的计算如下:
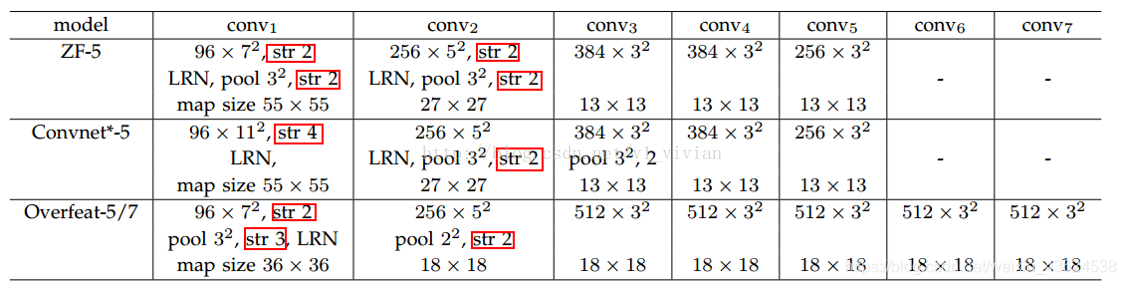
论文中使用的是
完整流程如下: