目标检测五
SSD
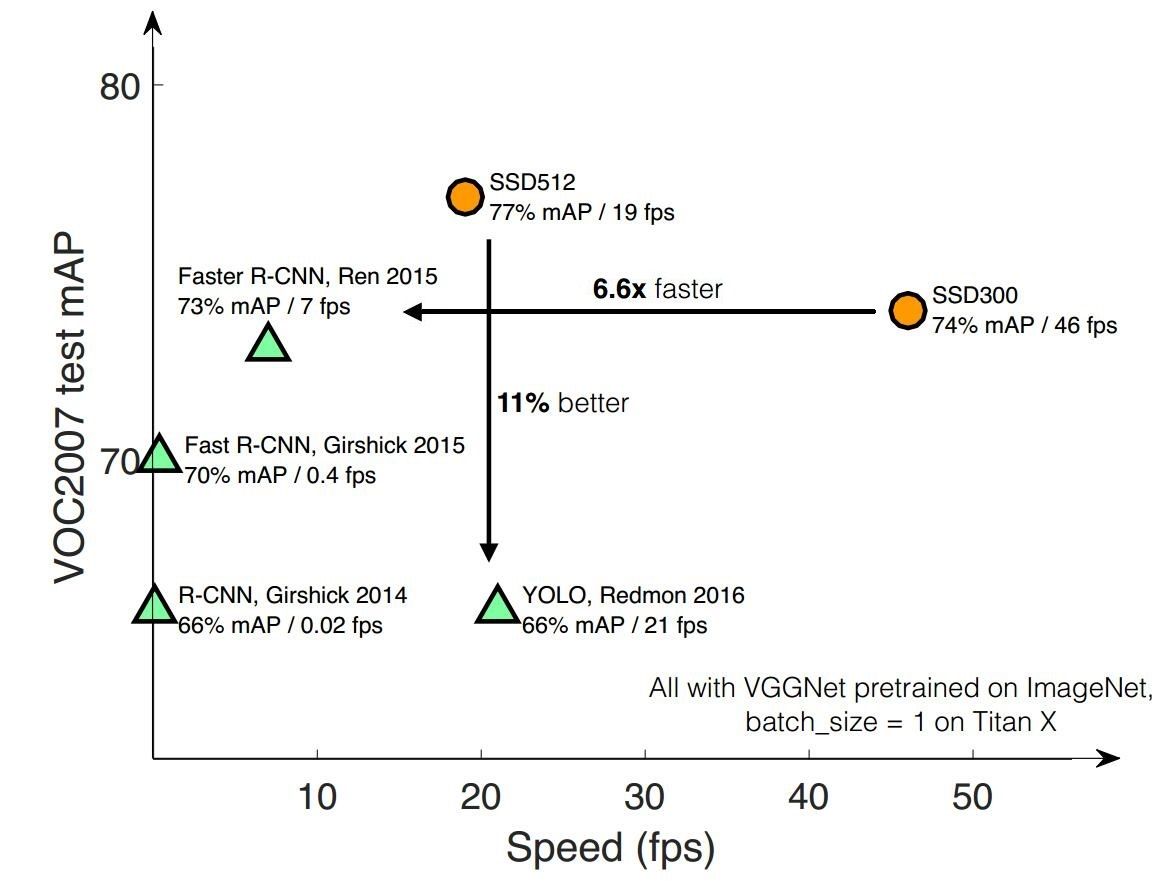
SSD,全称Single Shot MultiBox Detector,是Wei Liu在ECCV 2016上提出的一种目标检测算法,截至目前是主要的检测框架之一,相比Faster RCNN有明显的速度优势,相比YOLO又有明显的mAP优势(不过已经被CVPR 2017的YOLO9000超越)。
- 论文链接:https://arxiv.org/abs/1512.02325
- 论文翻译:https://blog.csdn.net/denghecsdn/article/details/77429978
- 论文详解:https://blog.csdn.net/WZZ18191171661/article/details/79444217
- 论文代码:https://github.com/balancap/SSD-Tensorflow
- 项目参考:https://blog.csdn.net/zzz_cming/article/details/81128460
- 参考:https://zhuanlan.zhihu.com/p/33544892
参考:https://zhuanlan.zhihu.com/p/31427288
SSD具有如下主要特点:
- 从YOLO中继承了将detection转化为regression的思路,一次完成目标定位与分类
- 基于Faster RCNN中的Anchor,提出了相似的Prior box;
- 加入基于特征金字塔(Pyramidal Feature Hierarchy)的检测方式,即在不同感受野的feature map上预测目标(FPN思路)
网络结构
算法步骤
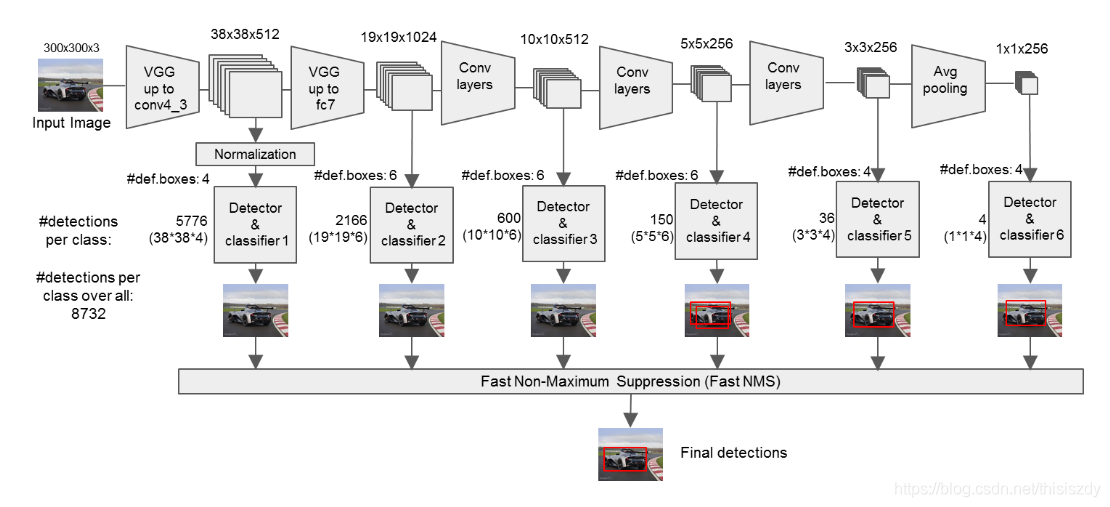
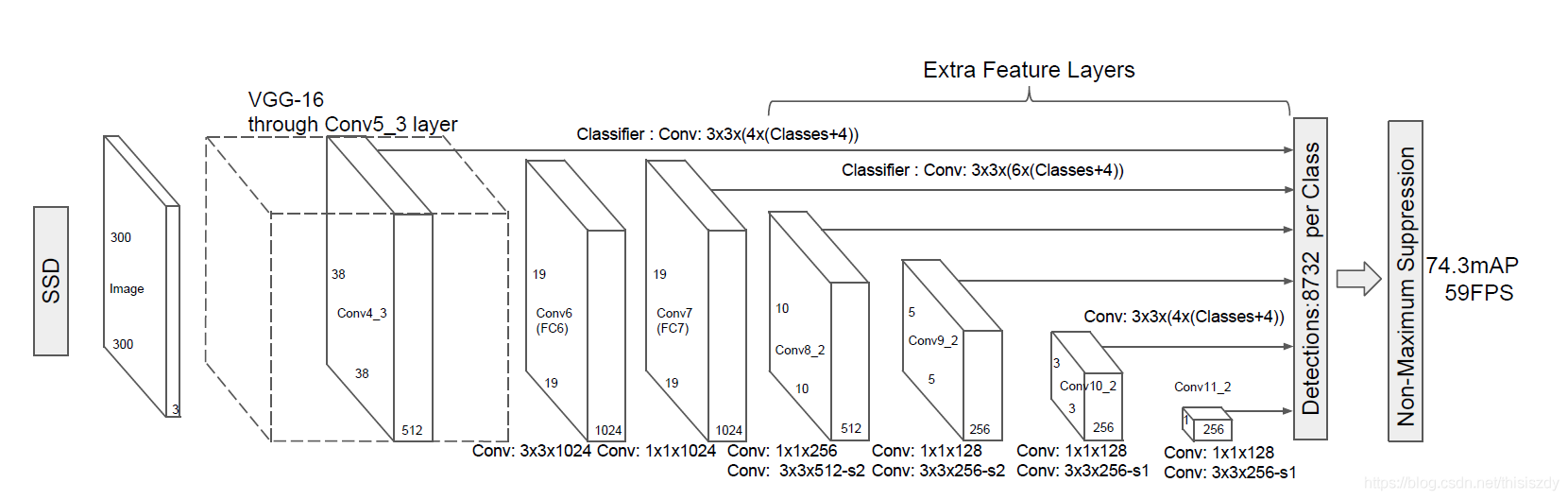
- 输入一幅图片(300x300),将其输入到预训练好的分类网络中来获得不同大小的特征映射,修改了传统的VGG16网络;
- 将VGG16的FC6和FC7层转化为卷积层,如图1上的Conv6和Conv7;
- 去掉所有的Dropout层和FC8层;
- 添加了Atrous算法(hole算法);
- 将Pool5从2x2-S2变换到3x3-S1;
- 抽取Conv4_3、Conv7、Conv8_2、Conv9_2、Conv10_2、Conv11_2层的feature map,然后分别在这些feature map层上面的每一个点构造6个不同尺度大小的bbox,然后分别进行检测和分类,生成多个bbox,如图2所示;
- 将不同feature map获得的bbox结合起来,经过NMS(非极大值抑制)方法来抑制掉一部分重叠或者不正确的bbox,生成最终的bbox集合(即检测结果);
Prior box
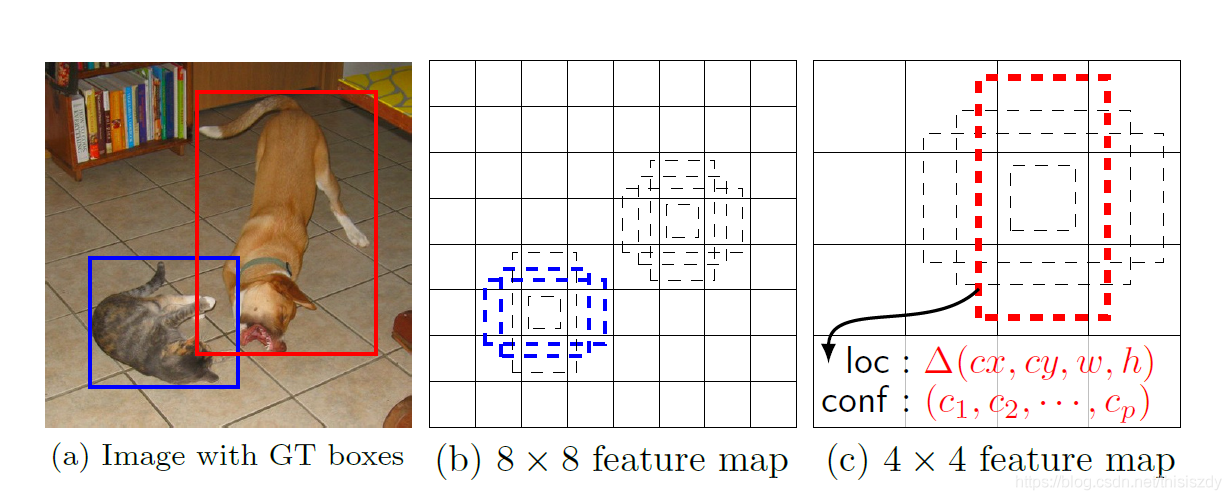 如上图所示,在特征图的每个位置预测K个bbox,对于每一个bbox,预测C个类别得分,以及相对于Prior box(Default box)的4个偏移量值,这样总共需要 (C+4)×K个预测器,则在m×n的feature map上面将会产生 (C+4)×K×m×n个预测值
如上图所示,在特征图的每个位置预测K个bbox,对于每一个bbox,预测C个类别得分,以及相对于Prior box(Default box)的4个偏移量值,这样总共需要 (C+4)×K个预测器,则在m×n的feature map上面将会产生 (C+4)×K×m×n个预测值
对于每个单元的每个先验框,其都输出一套独立的检测值,对应一个边界框,主要分为两个部分。第一部分是各个类别的置信度或者评分,值得注意的是SSD将背景也当做了一个特殊的类别,如果检测目标共有 $c$ 个类别,SSD其实需要预测 $c+1$ 个置信度值,其中第一个置信度指的是不含目标或者属于背景的评分。后面当我们说 $c$ 个类别置信度时,请记住里面包含背景那个特殊的类别,即真实的检测类别只有 $c-1$ 个。在预测过程中,置信度最高的那个类别就是边界框所属的类别,特别地,当第一个置信度值最高时,表示边界框中并不包含目标
作者认为仅仅靠同一层上的多个anchor来回归,还远远不够。因为有很大可能这层上所有anchor的IOU都比较小,就是说所有anchor离ground truth都比较远,用这种anchor来训练误差会很大。
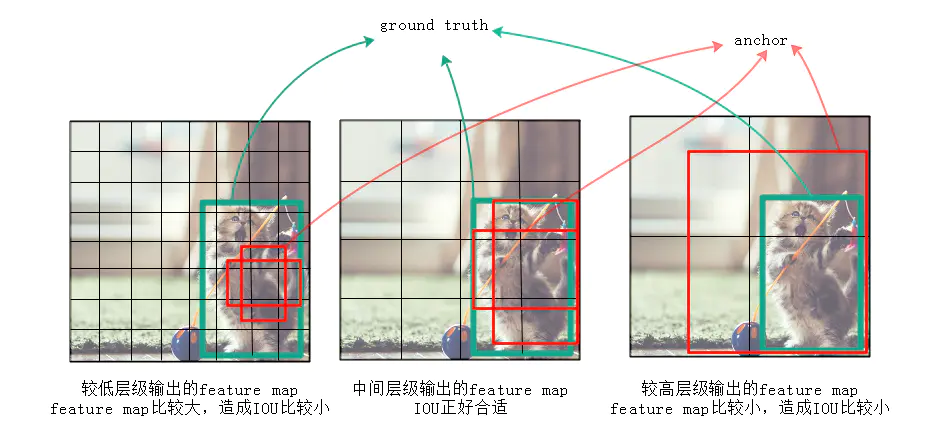
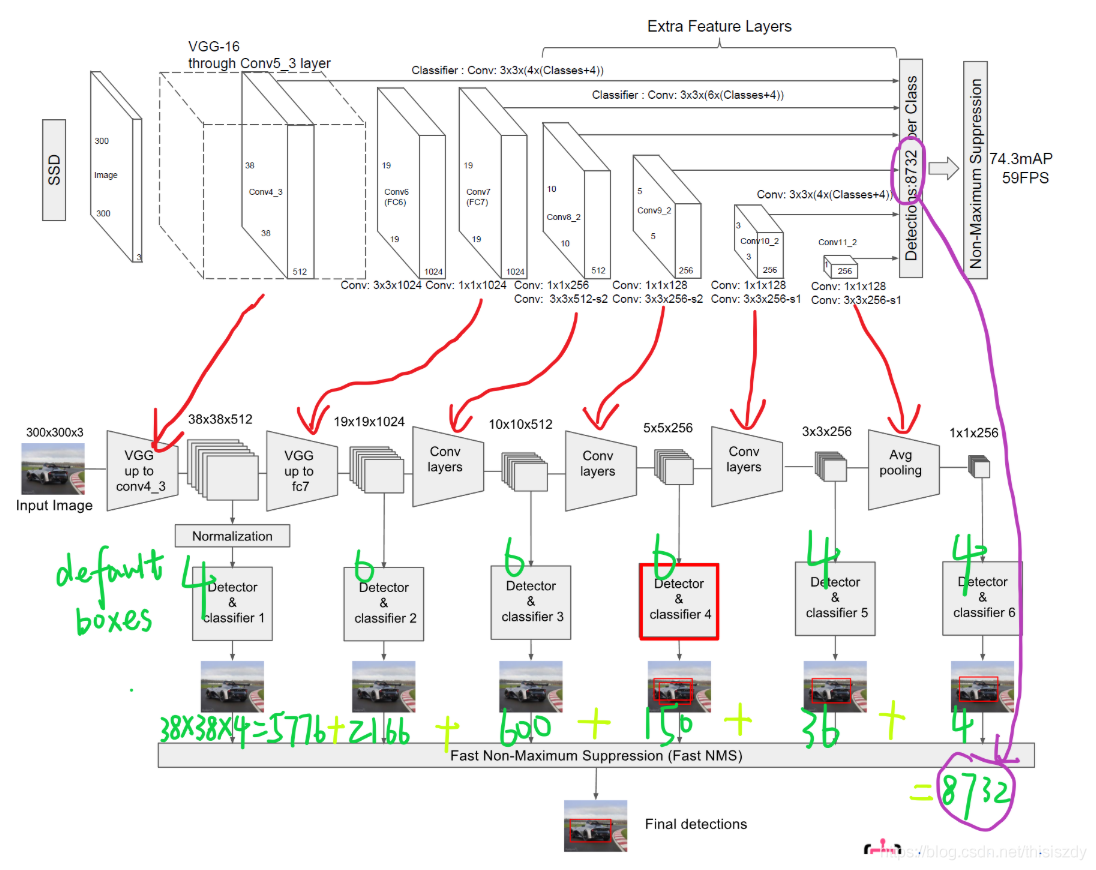
SSD中的Defalut box和Faster-rcnn中的anchor机制很相似。就是预设一些目标预选框,后续通过softmax分类+bounding box regression获得真实目标的位置。对于不同尺度的feature map 上使用不同的Default boxes。如上图所示,我们选取的feature map包括38x38x512、19x19x1024、10x10x512、5x5x256、3x3x256、1x1x256,Conv4_3之后的feature map默认的box是4个,我们在38x38的这个平面上的每一点上面获得4个box,那么我们总共可以获得38x38x4=5776个;同理,我们依次将FC7、Conv8_2、Conv9_2、Conv10_2和Conv11_2的box数量设置为6、6、6、4、4,那么我们可以获得的box分别为2166、600、150、36、4,即我们总共可以获得8732个box,然后我们将这些box送入NMS模块中,获得最终的检测结果。
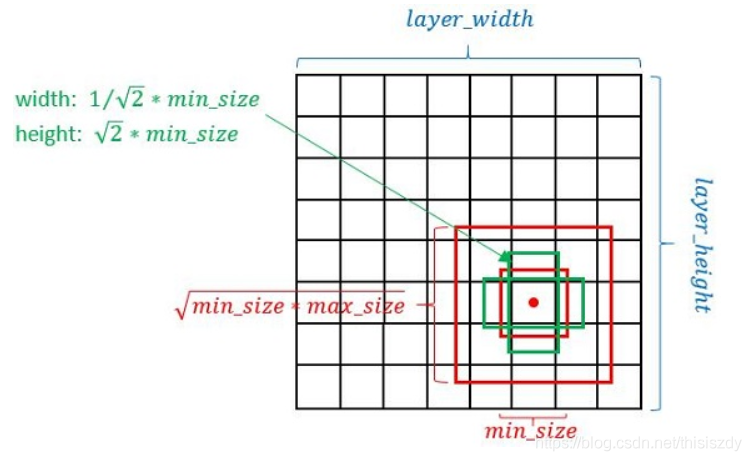
Prior box生成规则
- 以feature map上每个点的中点为中心(offset=0.5),生成一系列同心的Defalut box(然后中心点的坐标会乘以step,相当于从feature map位置映射回原图位置)
- 正方形prior box最小边长为$min_size$,最大边长为$\sqrt{min_size*max_size}$
每一个aspect radio会生成两个长方形,使用不同的ratio值,[1, 2, 3, 1/2, 1/3],长宽为$\sqrt{aspect_radio}min_size$和$\frac{1}{\sqrt{aspect_radio}}min_size$
使用m(SSD300中m=6)个不同大小的feature map 来做预测,最底层的 feature map 的 scale 值为 Smin=0.2,最高层的为Smax=0.9,其他层通过下面的公式计算得到:
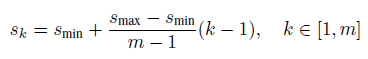
第一层feature map对应的min_size=S1*300,max_size=S2*300;第二层min_size=S2*300,max_size=S3*300;其他类推。在原文中,Smin=0.2,Smax=0.9,但是在SSD 300中prior box设置并不能和paper中上述公式对应:
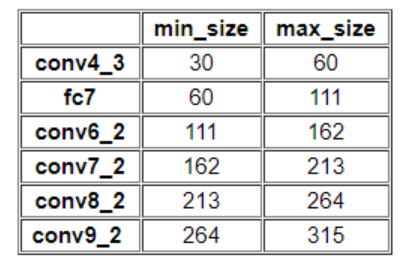
而对于ratio=0的情况,指定的scale如下所示,即总共有 6 中不同的 default box。
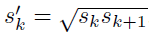
SSD使用低层feature map检测小目标,使用高层feature map检测大目标
先验框匹配
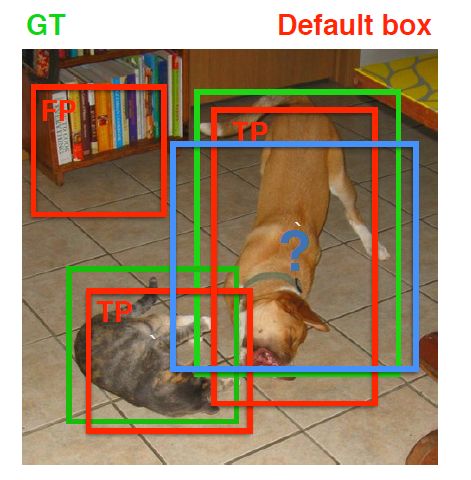
在训练过程中,首先要确定训练图片中的ground truth(真实目标)与哪个先验框来进行匹配,与之匹配的先验框所对应的边界框将负责预测它。在Yolo中,ground truth的中心落在哪个单元格,该单元格中与其IOU最大的边界框负责预测它。但是在SSD中却完全不一样,SSD的先验框与ground truth的匹配原则主要有两点。首先,对于图片中每个ground truth,找到与其IOU最大的先验框,该先验框与其匹配,这样,可以保证每个ground truth一定与某个先验框匹配。通常称与ground truth匹配的先验框为正样本(其实应该是先验框对应的预测box,不过由于是一一对应的就这样称呼了),反之,若一个先验框没有与任何ground truth进行匹配,那么该先验框只能与背景匹配,就是负样本。一个图片中ground truth是非常少的, 而先验框却很多,如果仅按第一个原则匹配,很多先验框会是负样本,正负样本极其不平衡,所以需要第二个原则。第二个原则是:对于剩余的未匹配先验框,若某个ground truth的 $IOU$ 大于某个阈值(一般是0.5),那么该先验框也与这个ground truth进行匹配。这意味着某个ground truth可能与多个先验框匹配,这是可以的。但是反过来却不可以,因为一个先验框只能匹配一个ground truth,如果多个ground truth与某个先验框 $IOU$大于阈值,那么先验框只与IOU最大的那个ground truth进行匹配。第二个原则一定在第一个原则之后进行,仔细考虑一下这种情况,如果某个ground truth所对应最大 $IOU$小于阈值,并且所匹配的先验框却与另外一个ground truth的 $IOU$大于阈值,那么该先验框应该匹配谁,答案应该是前者,首先要确保某个ground truth一定有一个先验框与之匹配。但是,这种情况我觉得基本上是不存在的。由于先验框很多,某个ground truth的最大 $IOU$肯定大于阈值,所以可能只实施第二个原则既可以了,这里的TensorFlow版本就是只实施了第二个原则,但是这里的Pytorch两个原则都实施了。图8为一个匹配示意图,其中绿色的GT是ground truth,红色为先验框,FP表示负样本,TP表示正样本。
尽管一个ground truth可以与多个先验框匹配,但是ground truth相对先验框还是太少了,所以负样本相对正样本会很多。为了保证正负样本尽量平衡,SSD采用了hard negative mining,就是对负样本进行抽样,抽样时按照置信度误差(预测背景的置信度越小,误差越大)进行降序排列,选取误差的较大的top-k作为训练的负样本,以保证正负样本比例接近1:3。
预测过程
预测过程比较简单,对于每个预测框,首先根据类别置信度确定其类别(置信度最大者)与置信度值,并过滤掉属于背景的预测框。然后根据置信度阈值(如0.5)过滤掉阈值较低的预测框。对于留下的预测框进行解码,根据先验框得到其真实的位置参数(解码后一般还需要做clip,防止预测框位置超出图片)。解码之后,一般需要根据置信度进行降序排列,然后仅保留top-k(如400)个预测框。最后就是进行NMS算法,过滤掉那些重叠度较大的预测框。最后剩余的预测框就是检测结果了。
训练技巧
数据增强
SSD训练过程中使用的数据增强对网络性能影响很大,大约有6.7%的mAP提升。
- 随机剪裁:采样一个片段,使剪裁部分与目标重叠分别为0.1, 0.3, 0.5, 0.7, 0.9,剪裁完resize到固定尺寸。
- 以0.5的概率随机水平翻转。
conv4_3检测
基础网络部分特征图分辨率高,原图中信息更完整,感受野较小,可以用来检测图像中的小目标,这也是SSD相对于YOLO检测小目标的优势所在。增加对基础网络conv4_3的特征图的检测可以使mAP提升4%。
长方形默认框
挑选合适形状的默认框能够提高检测效果。作者实验得出使用瘦高与宽扁默认框相对于只使用正方形默认框有2.9%mAP提升。
使用atrous卷积
通常卷积过程中为了使特征图尺寸特征图尺寸保持不变,通过会在边缘打padding,但人为加入的padding值会引入噪声,因此,使用atrous卷积能够在保持感受野不变的条件下,减少padding噪声,关于atrous参考。本文SSD训练过程中并且没有使用atrous卷积,但预训练过程使用的模型为VGG-16-atrous,意味着作者给的预训练模型是使用atrous卷积训练出来的。使用atrous版本VGG-16作为预训模型比较普通VGG-16要提高0.7%mAP。
Loss
loss函数分为两部分:计算相应的default box与目标类别的confidence loss以及相应的位置回归。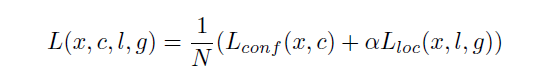
其中N先验框的正样本数量, 这里 $x^p_{ij}\in{1,0}$ 为一个指示参数,当 $x^p_{ij}=1$ 时表示第 $i$个先验框与第 $j$个ground truth匹配,并且ground truth的类别为$j$。 !$c$为类别置信度预测值。$l$为先验框的所对应边界框的位置预测值,而$g$是ground truth的位置参数 ;而alpha参数用于调整confidence loss和location loss之间的比例,默认alpha=1。
位置回归则是采用 Smooth L1 loss,loss函数为: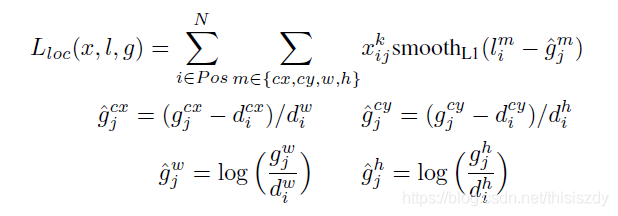
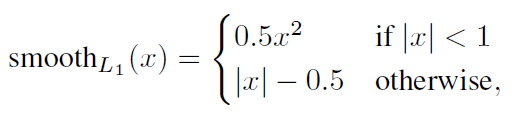
由于 $x_{ij}^p$ 的存在,所以位置误差仅针对正样本进行计算。值得注意的是,要先对ground truth的$g$进行编码得到 $\hat{g}$ ,因为预测值$l$也是编码值,若设置variance_encoded_in_target=True,编码时要加上variance:
![[公式]](/2020/10/16/目标检测五/equation-1602921623311.svg)
![[公式]](/2020/10/16/目标检测五/equation-1602921623385.svg)
confidence loss是典型的softmax loss: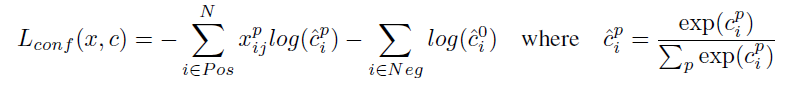
Retina NET
代码地址:https://github.com/facebookresearch/Detectron
论文地址:https://arxiv.org/abs/1708.02002
Focal loss
主要贡献为提出了Focal Loss, 解决了one-stage算法中正负样本的比例严重失衡的问题,不需要改变网络结构 。
当样本不均衡的时候,如负样本很大,而且很多都是容易分类的(置信度很高的),这样模型的优化方向就不是我们想要的方向,我是想让正负样本分开的,所以我们要把很多的注意力放在困难、难分类的样本上,所以作者在标准交叉熵损失的基础上进行了改进,首先我们把交叉熵二分类loss定义为:
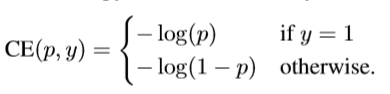
然后 $y\in{-1,1}$表示正负样本的标签,$p$ 表示模型预测 $y=1$的概率,所以我们定义$p_t$ 如下:
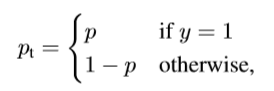
然后我们重写交叉熵损失为 ![[公式]](/2020/10/16/目标检测五/equation-1602922318460.svg)
- 首先我们要解决样本不平衡的问题,我们使用一个平衡因子 $\alpha_t$ ,其范围是0到1,对于类别1乘以$\alpha_t$ ,而对于类别-1乘以$1-\alpha_t$ ,然后我们把损失函数重写为:
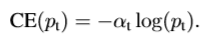
- 虽然上面的方法使得可以调节正负样本对loss的贡献度,但是我们希望那些容易分的样本(置信度高的)提供的loss小一些,而那些难分的样本提供的loss几乎不变化,让分类器优化的方向更关注那些难分的样本。
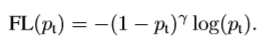
假如有这么一个样本,且 $\gamma=2$时,如果其$p_t=0.9$ 时,FL loss会比原来的CE loss小100多倍,如果其 $p_t=0.968$ ,那就会小1000多倍。
最后我们把完整版的loss函数写下来,为:
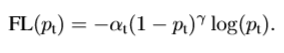
本文中,将$\gamma$定义为2时效果最好!
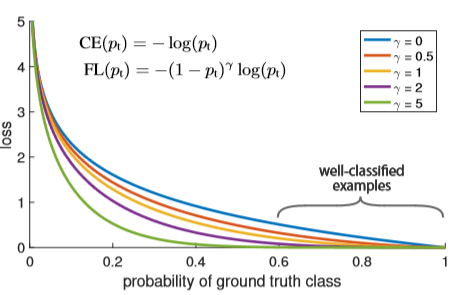
可以看出,蓝色的线为CE loss, 随着$\gamma$ 的增加,那些容易分类的样本所贡献的loss就越小,所以可以使模型的优化方向更加关注那些难分类的样本,这样就可以提高模型的精度,同时兼顾了速度。