EfficientNet
EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
论文链接: https://arxiv.org/pdf/1905.11946.pdf
官方源码: https://github.com/tensorflow/tpu/tree/master/models/official/efficientnet
第三方PyTorch源码: https://github.com/lukemelas/EfficientNet-PyTorch
简介
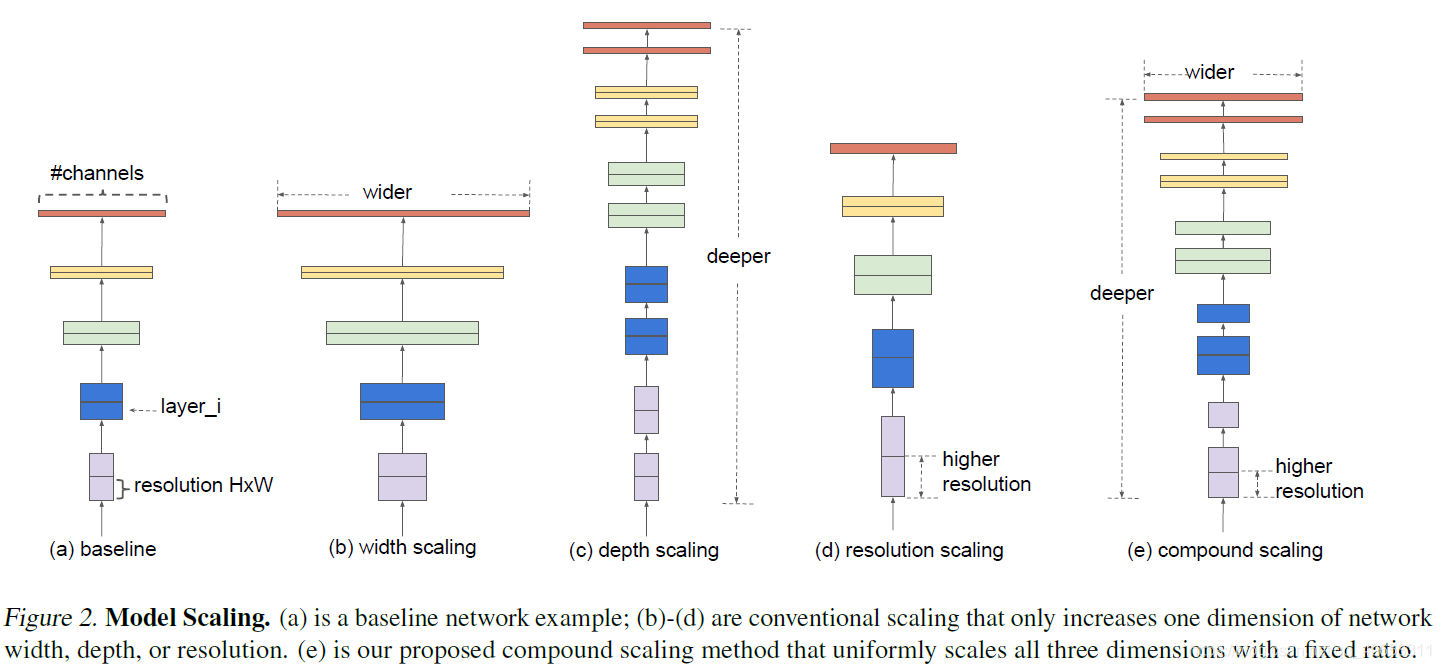
一般情况下通过扩大网络深度、宽度、分辨率(如Gpipe采用480*480的图像) 来提升模型精度。作者提出了一种compound scaling method ,综合考虑深度、宽度、分辨率。
Depth、Width、Resolution
一个卷积层$i$可以被定义为一个函数:$Y_i = F_i ( X_i )$,其中是$F_i$卷积操作,$Y_i$是输出的张量,$X_i$是输入的张量且张量的形状为$(H_i, W_i, C_i)$。此外CNN通常被划分为多个阶段,每个阶段的所有层结构是相同的,比如ResNet中有五个阶段,每个阶段的所有层都具有相同的卷积类型,除了第一层执行下采样。因此一个神经网络$N$可以表示为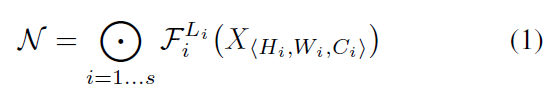
其中$F_i^{L_i}$表示在第$i$个阶段的第$L_i$次重复的$F_i$层,$(H_i,W_i,C_i)$是第$i$层输入的张量$X$形状。不同于之前普通的网络设计是集中在寻找更好的$F_i$层架构,模型缩放则是扩展网络长度、宽度和分辨率($H_i,W_i$)而不改变baseline网络中的$F_i$。为了进一步减少设计空间的大小,限制所有参数必须以恒定的比例均匀地缩放。目标是为了在给定资源限制时最大化模型精度,可以被定义为一个优化问题: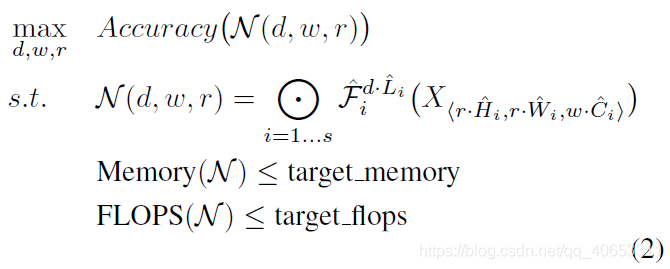
其中$w,d,r$是对网络的宽度、深度和分辨率缩放的参数,$\hat{F_i},\hat{L_i},\hat{H_i},\hat{W_i},\hat{C_i}$是baseline网络中预先定义好的参数
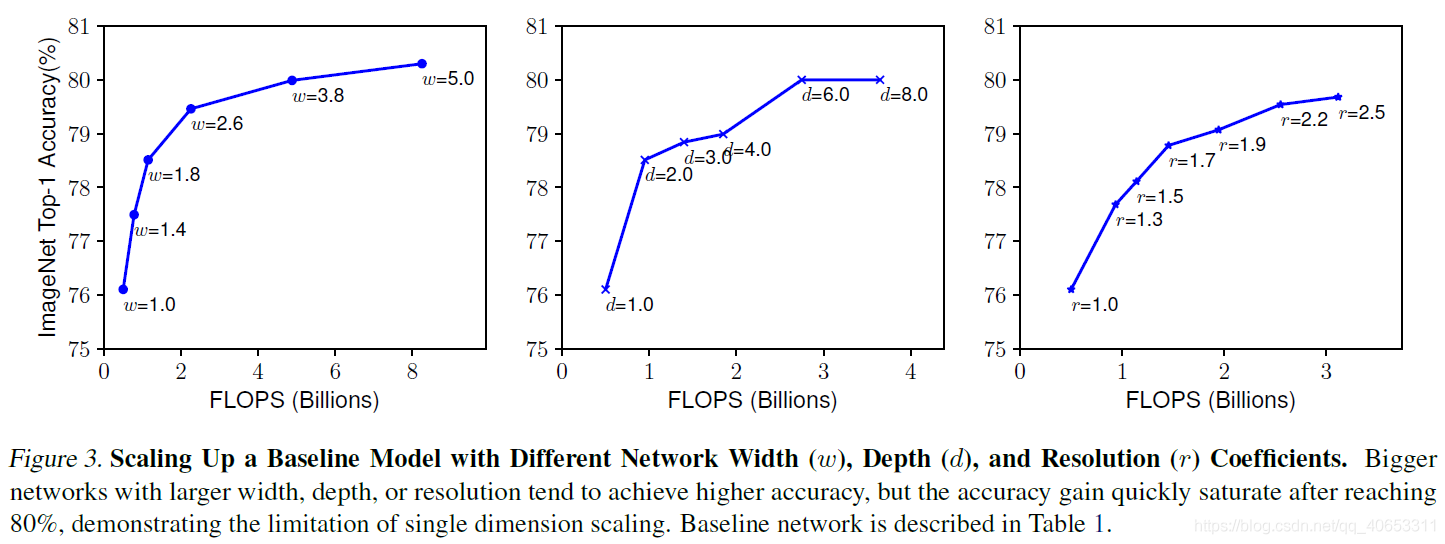
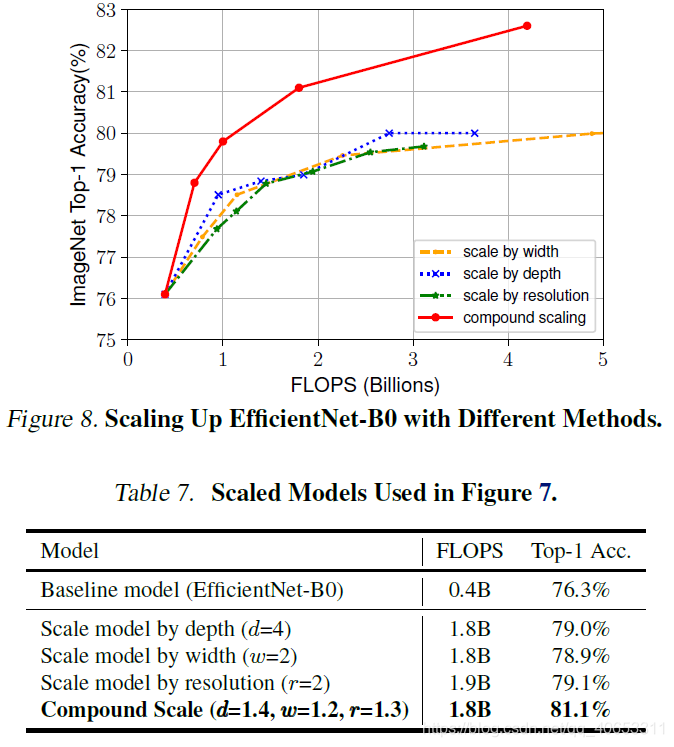
通过增加宽度、深度、分辨率都可以一定程度上提升准确率。但是对于大型网络提升有限(ResNet 1000 和 ResNet 101准备率相似)
可以看到当精度达到80%左右时会饱和。
Compound scaling method
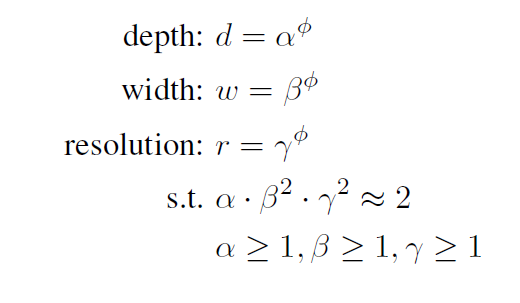
$α,β,γ$是可以通过小型网格搜索确定的常量,而$ϕ$从直观上解释是是用户按照能够提供的额外计算资源开销(相对于baseline将网络扩展时需要额外计算资源)的多少来指定的参数。$α , β , γ$则是确定如何分别为网络宽度、深度和分辨率分配这些额外资源。
常规卷积运算的FLOPS与$d,w^2,r^2$成正比,例如将网络深度加倍会加倍FLOPS,而将网络宽度或者分辨率加倍会使得FLOPS大致增加四倍,因此用上述公式对网络进行缩放时,会使得总体FLOPS增加大约$(\alpha\cdot\beta^2\cdot\gamma^2)^ϕ$倍,在本文中,通过约束$ \alpha\cdot\beta^2\cdot\gamma^2\approx2$使得对任意的$\phi$整体的FLOPS将会增加$2^\phi$倍
EfficientNet Architecture
首先作者使用MnasNet的方法,利用多目标神经网络架构搜索,同时优化准确率和FLOPS,得到了FLOPS为400M的baseline网络EfficientNet-B0,网络架构如下表
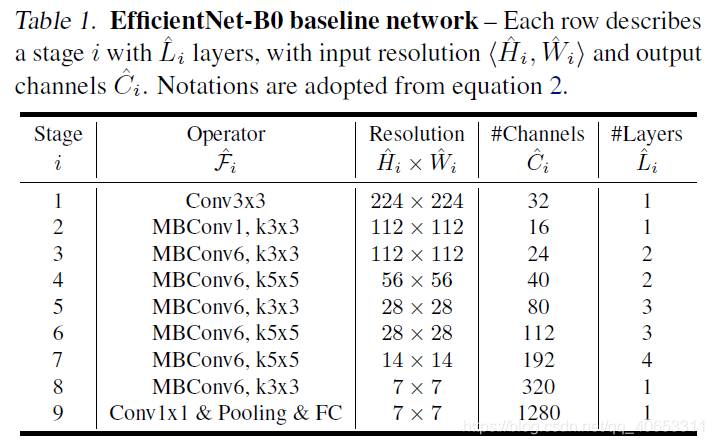
然后从这个baseline着手,使用两个步骤:
- STEP 1: 固定$\phi=1$,即假设有两倍以上的可用资源,并做一个小的网格搜索得到了最佳值$α = 1.2 , β = 1.1 , γ = 1.15$,在$\alpha\cdot\beta^2\cdot\gamma^2\approx2$的约束下。这样做的原因是因为在大模型上搜索成本太高了。
STEP 2: 固定$\alpha,\beta,\gamma$并使用不同的$\phi$对baseline网络进行扩展,得到了EfficientNet-B1到B7
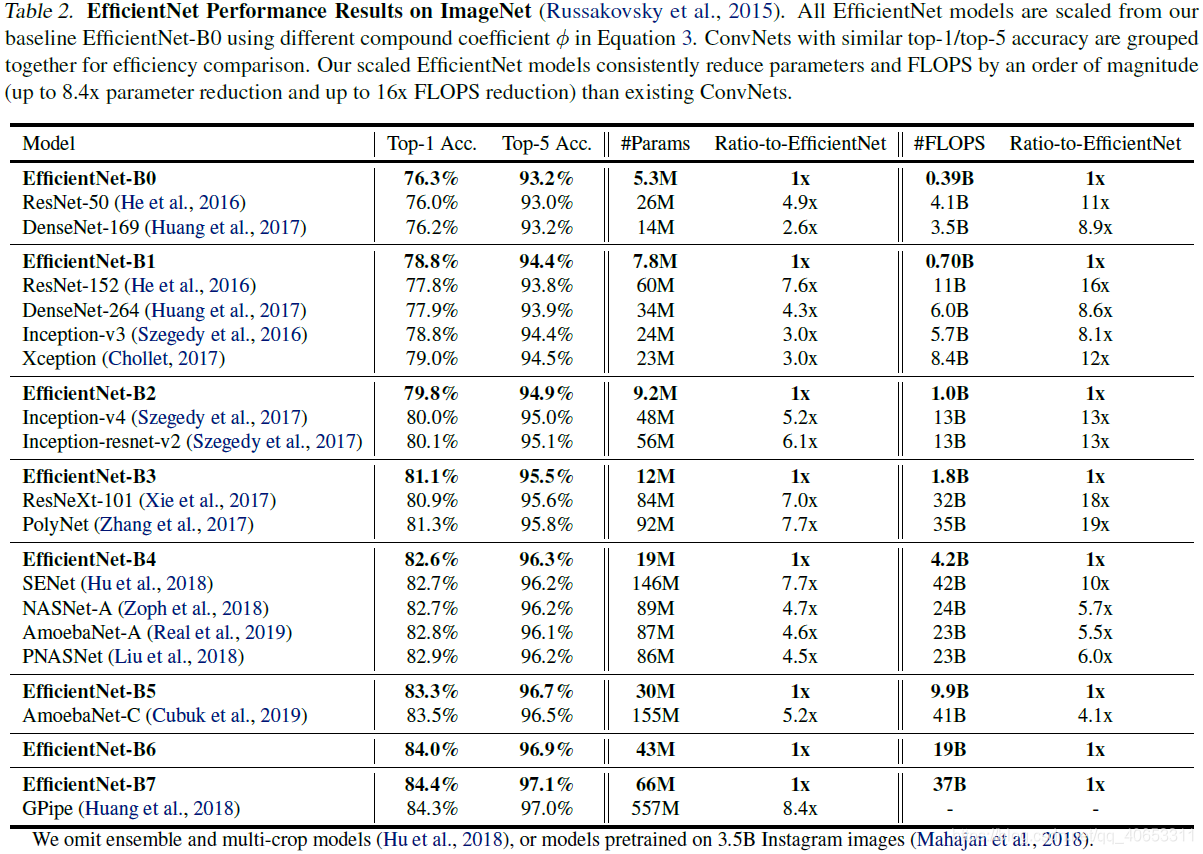
结果
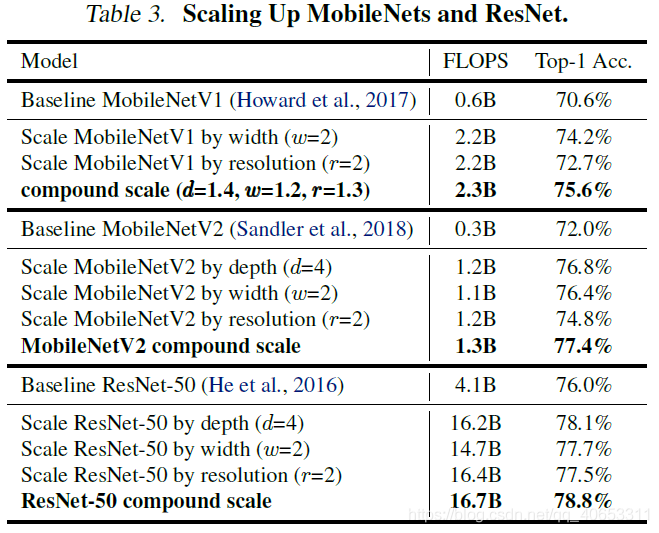
对MobileNet和ResNet采用这种方法进行网络扩展
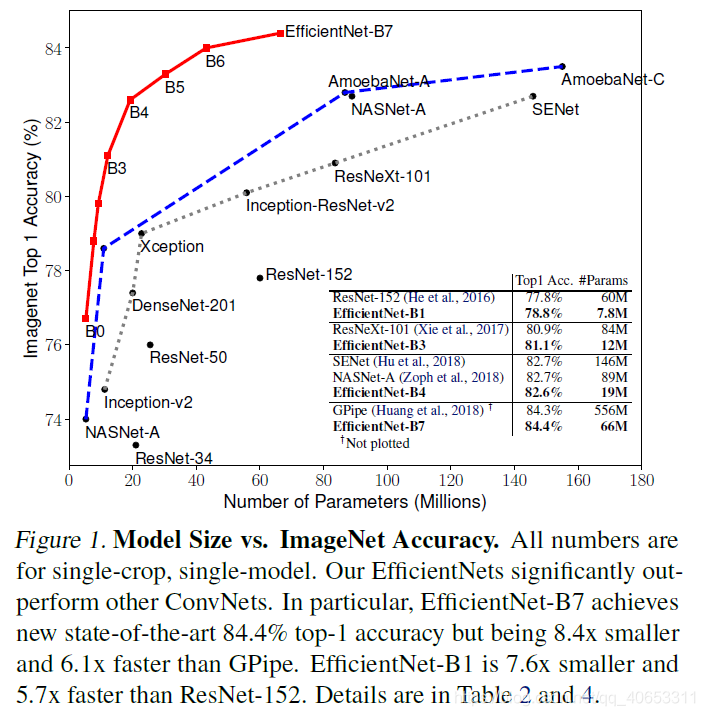
在ImageNet上的模型参数量与精度对比图
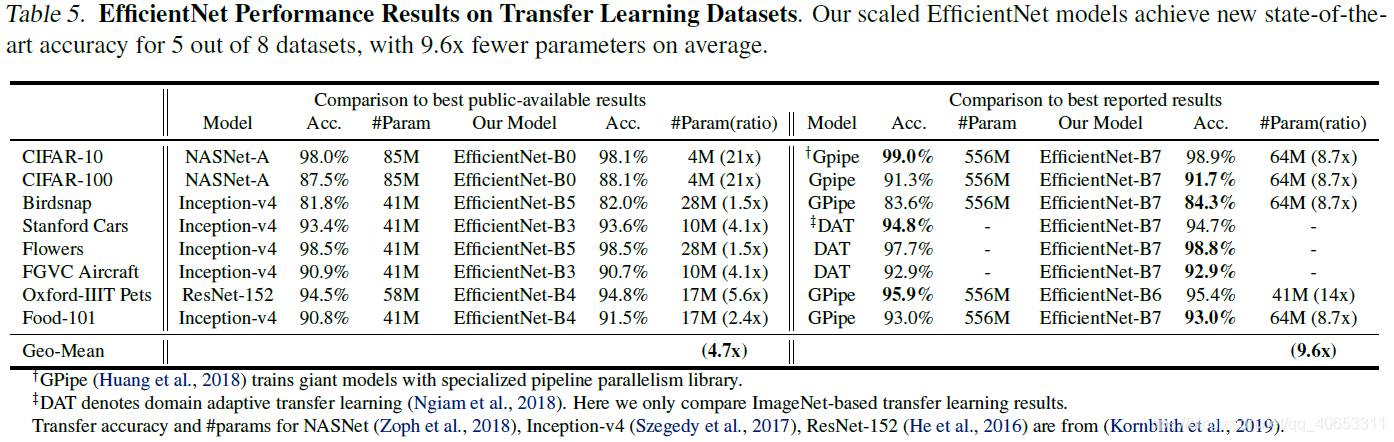
在其它数据集上迁移学习的效果,在5个数据集上达到了SOTA,参数平均减少9.6倍。
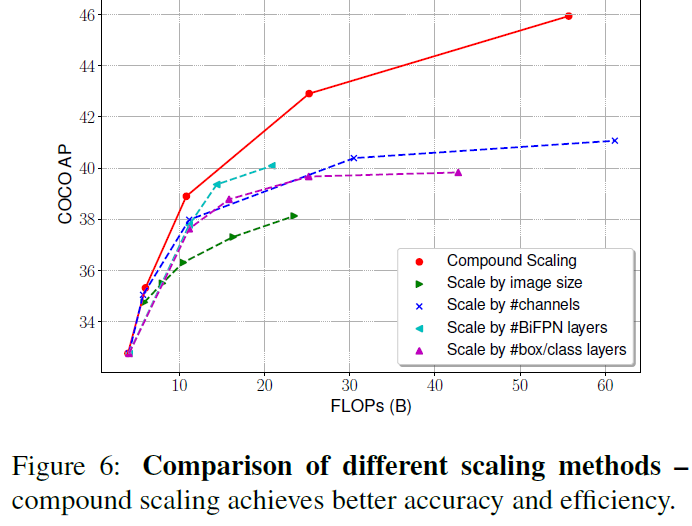
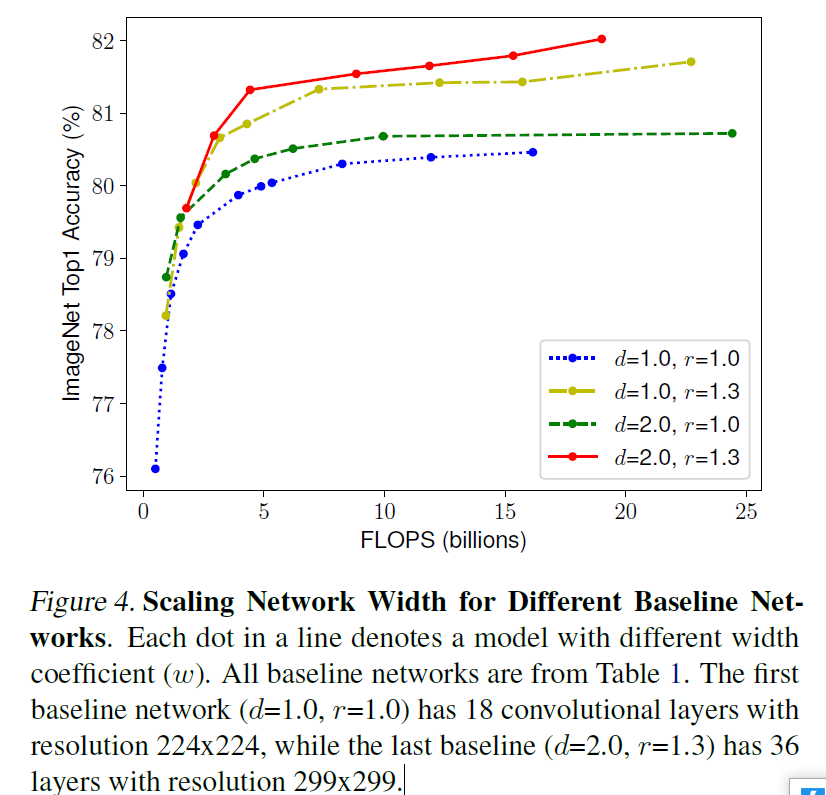
可以看出复合缩放方法比任何单一效果都好
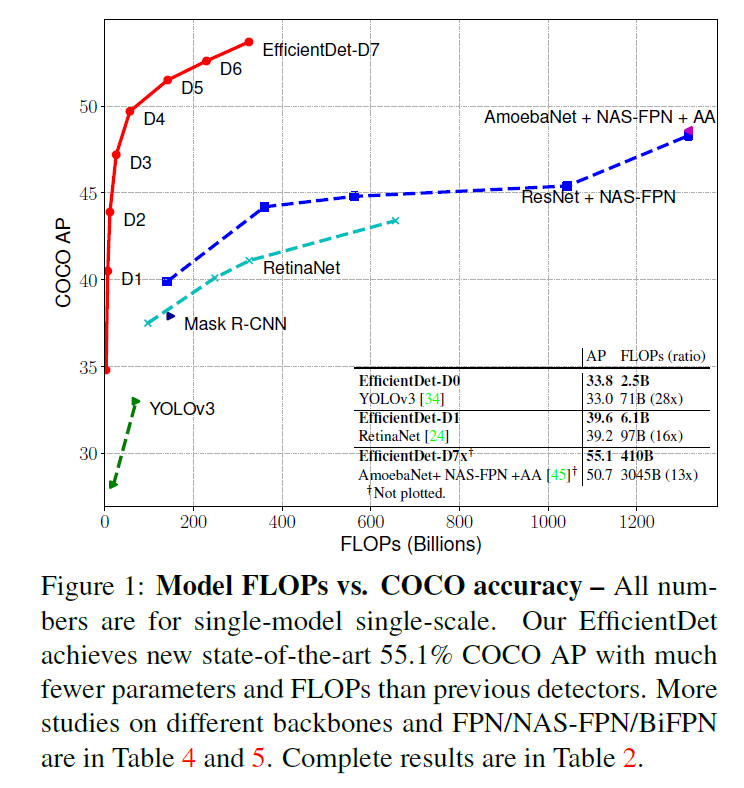
EfficientDet: Scalable and Efficient Object Detection
EfficientDet-D7 :在 326B FLOPS,参数量 52 M的情况下,COCO 2017 validation 数据集上取得了 51.0 的 mAP,state-of-the-art 的结果。和 AmoebaNet + NAS-FPN 相比,FLOPS 仅为其十分之一的情况下取得了更好的结果
本文首先提出了两个挑战:
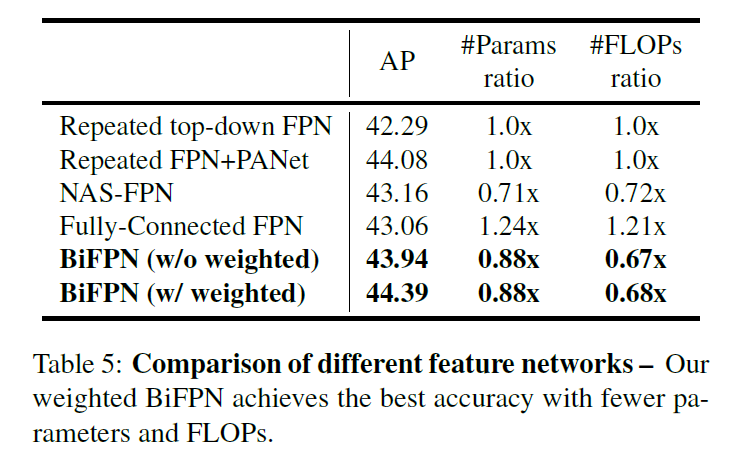
- efficient multi-scale feature fusion .之前的多尺度特征融合方式FPN、PANet、NAS_FPN等,在融合不同的输入特征时,只是不加区分地简单相加。但是,由于这些不同输入特征的分辨率不同,通常它们对融合后的输出特征的贡献不并相同。为了解决这个问题,本文提出双向加权特征金字塔网络(weighted bi-directional feature pyramid network (BiFPN) ),它使用了可学习的权重,来学习不同输入特征的贡献,并重复应用在自上而下和自下而上的多尺度特征融合中。
- model scaling. 借助之前提出的EfficientNet网络,提出了应用在目标检测领域的compound scaling method。将EfficientNet的主干网络与BiFPN结合,提出了新的目标检测网络,EfficientDet,同时在语义分割领域也取得了更好的效果。
BiFPN
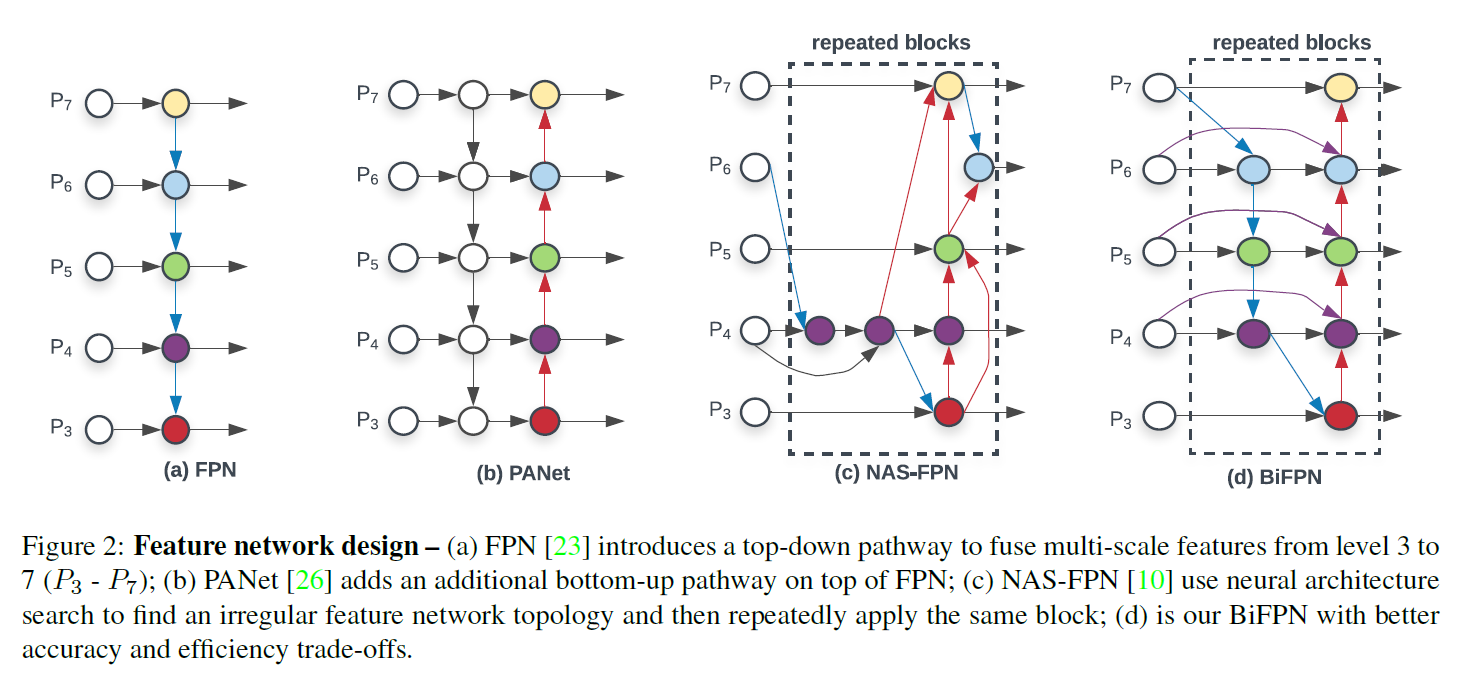
FPN:

NAS-FPN : 使用neural architecture search来搜索更好的跨尺度特征网络拓扑,但是在搜索过程中需要数千个GPU小时,并且网络是不规则的,难以解释或修改。
PANet: 在FPN基础上增加了额外的自下而上的网络融合路径。
三种方式中,PANet精度最高,但是参数和计算量最多。
本文提出的优化方法:
- 删除只有一个输入边的节点。理由是我们的目的是融合不同特征,而只有一个输入的节点没有进行特征融合,因此它的贡献较小。
- 如果原始输入节点和输出节点在同一层,那么增加一条额外的边,以便在不增加过多cost的情况下融合更多特征。
- 和PANet只有一条top-down和bottom-up路径不同,我们将每一条双向路径视为一个特征网络层,并通过将这个层重复多次来实现更高级别的特征融合。
Weighted Feature Fusion
为了解决不同层特征贡献不同的问题,对于每一个输入都增加一个权重,让网络去学习不同输入特征的重要性。基于这个想法,提出了三种加权特征融合方式:
- Unbounded fusion :$O=\sum_iw_i.I_i$,$w_i$是可学习的权重,形式可以是scalar(pre-feature),vector(per-channel),multi-dimensional tensor(per-pixel),scalar可以取得和其他方法相近的精度,并有着最小的cost,但是scalar weight is unbounded,所以可能导致训练不稳定,因此,使用weight normalization来限定weight取值范围
- Softmax-based fusion:$O=\sum_i\frac{e^{w_i}}{\sum_je^{w_j}}·I_i$,直观的想法是应用Softmax,将所有权重归一化到0~1,表示其重要性。但根据消融分析,额外的Softmax会导致GPU减速。
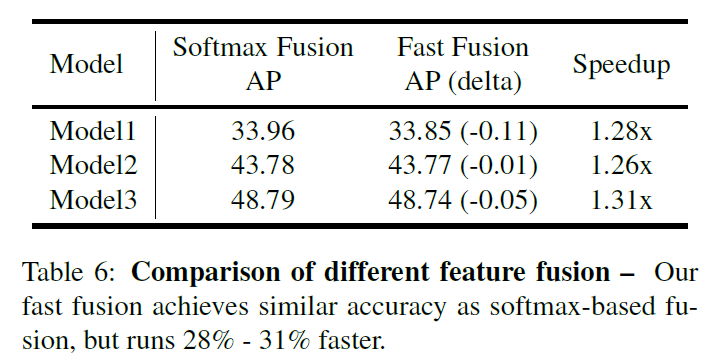
- Fast normalization fusion:$O=\sum_i\frac{w_i}{\epsilon+\sum_jw_j}·I_i$,通过在每个$w_i$后加Relu层来保证$w_i\geq0$,同时$\epsilon=0.0001$来避免数值不稳定。这样值也会归一化,但因为没有Softmax层会更加高效。通过消融分析证明这种方法和基于Softmax的方法表现和精度相当,但在GPU上会快30%。
level6 for BiFPN shown in Figure 2(d):

EfficientDet
EfficientDet Architecture
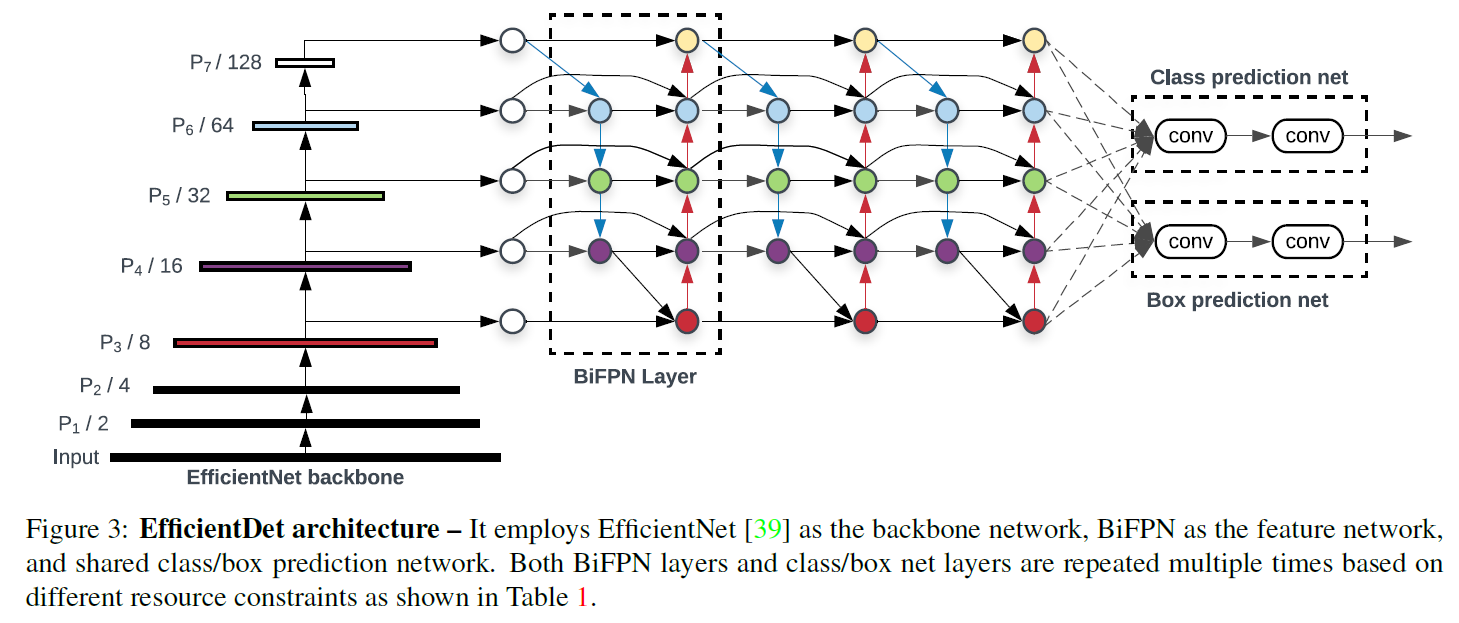
Compound Scaling
和EfficientNet不同的是,和分类模型相比目标检测有更多的scaling dimensions,所以在所有dimension上进行grid search代价过高。因此采用启发式scaling方法,但思想上仍然是联合放大所有维度。
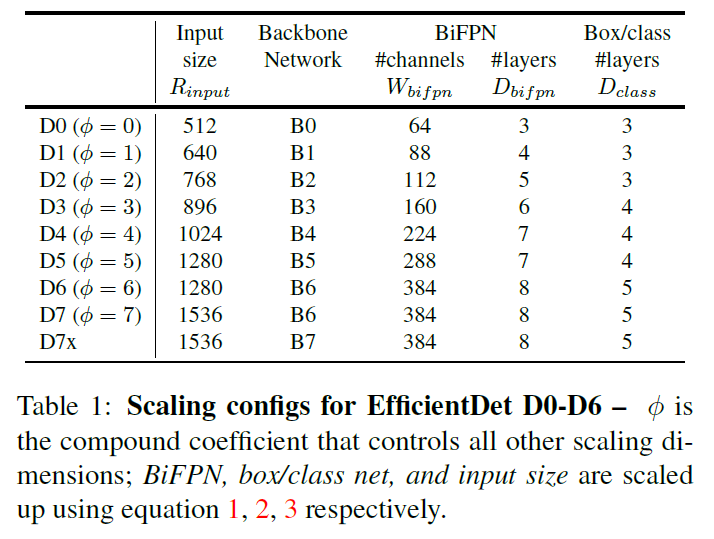
- Backbone network:和EfficientNet B0-B6使用相同的放大系数。
- BiFPN network:

- Box/class prediction network:它的宽度和BiFPN保持一致($W_{pred}=W_{bifpn}$),深度线性增加:$D_{box}=D_{class}=3+\left \lfloor \phi/3 \right \rfloor$
- Input image resolution:因为BiFPN使用了3-7层的特征,所以输入的分辨率需要能被$2^7=128$整除:$R_{input}=512+\phi·128$,
基于以上三个公式,拓展开发了EfficientDet D0-D7。
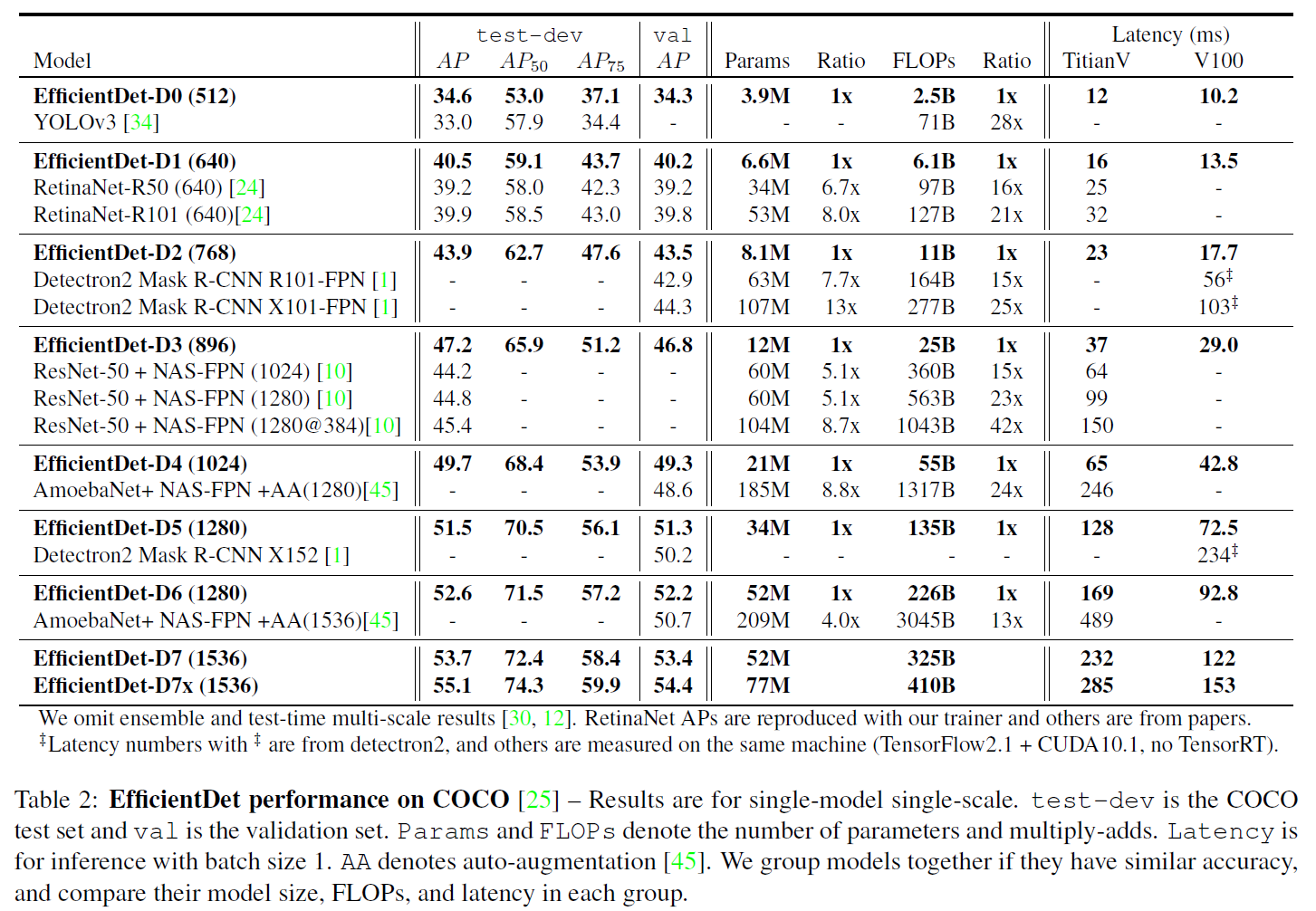
Ablation Study
Disentangling Backbone and BiFPN
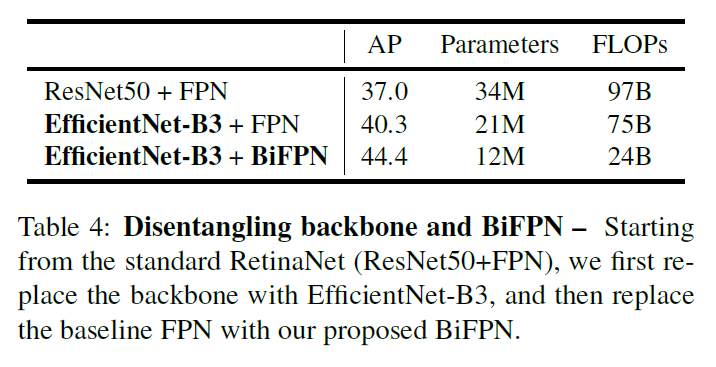
BiFPN CrossScale Connections
Softmax vs Fast Normalized Fusion
Compound Scaling