血细胞检测
使用faster R-CNN框架,csv自定义数据集。基于tensorflow和keras。
数据集处理
csv文件要求的格式为:filepath,x1,y1,x2,y2,class_name
BCCD数据集中已经给好了一个csv格式的test:

train.txt test.txt给出了训练集和测试集的图片名:
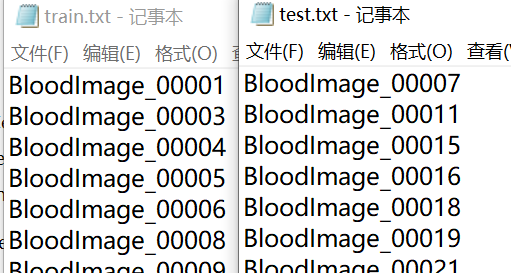
将给出的test.csv重命名为all.csv,按照train.txt和test.txt给出相应的train.csv和test.csv
1 | import csv |
训练时需要的是txt文件,将csv转为txt
1 | import pandas as pd |
train
1 | cd keras-frcnn |
test
测试时需要把测试用的图片放到一个文件夹下
1 | import pandas as pd |
test_frcnn.py最后改成
1 | # cv2.imshow('img',img) |
结果
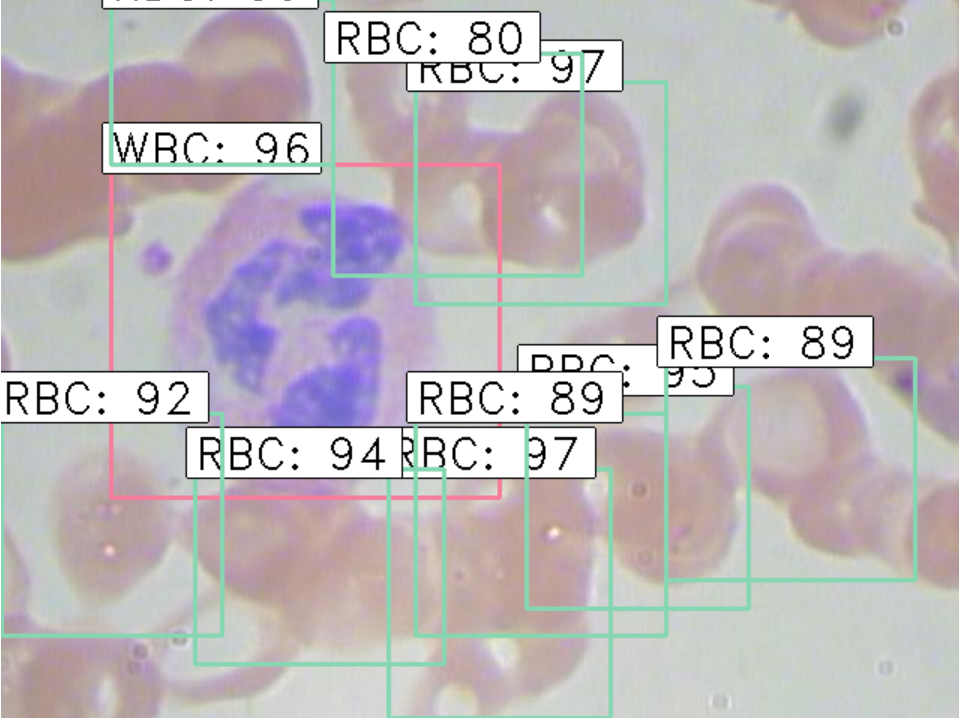
RetinaNet on coco
coco数据集在aistudio里下载
1 | 用coco数据集的话,整理成以下形式 |
coco
训练
1 | python train.py --dataset coco --coco_path E:\Python\ObjDetection\datasets\val2017 --depth 50 |
测试
1 | python coco_validation.py --coco_path E:\Python\ObjDetection\datasets\val2017 --model_path ./coco_resnet_50_map_0_335_state_dict.pt |
指定图片可视化
将需要可视化的图片放到visual文件夹里
需要修改一部分代码,源码只加载了state_dict没有指定模型,在visulize_single_image.py中导入retinanet
from retinanet import model,然后代码里先指定模型
1 | retina = model.resnet50(num_classes=80) |
1 | python visualize_single_image.py --image_dir ./visual --model_path ./coco_resnet_50_map_0_335_state_dict.pt --class_list ./coco_classes_list.csv |
这种方法还需要生成coco的classes_list格式为 class_name,id

coco可视化
同样需要加载retinanet模型
1 | retinanet = model.resnet50(num_classes=80) |
1 | python visualize.py --dataset coco --coco_path ...\datasets\val2017 --model ./coco_resnet_50_map_0_335_state_dict.pt |

按下键换下一张图片
csv
按照要求生成如下格式的csv文件,‘path/to/image.jpg,x1,y1,x2,y2,class_name’
用百度的fruit数据集,解析xml文件,生成train.csv、test.csv、classes.csv
1 | <annotation> |
1 | import csv |
训练
Unexpected bus error encountered in worker. This might be caused by insufficient shared memory (shm)出现这个错误的情况是,在服务器上的docker中运行训练代码时,batch size设置得过大,shared memory不够(因为docker限制了shm).解决方法是,将Dataloader的num_workers设置为0.
1 | CUDA_VISIBLE_DEVICES=4 python ./train.py --dataset csv --csv_train ./csv/train1.csv --csv_classes ./csv/classes.csv --csv_val ./csv/val1.csv |
Attempted to read a PyTorch file with version 3, but the maximum supported version for reading is 2.
因为服务器版本和本机版本不一致,但更新了conda还是不行
修改visualize_single_image
1 | # cv2.imshow('detections', image_orig) |
直接将图片保存在服务器上
1 | CUDA_VISIBLE_DEVICES=4 python ./visualize_single_image.py --image_dir ./visual_fruit --model_path ./checkpoint/model_final.pt --class_list ./fruit_classes_list.csv |

