image caption综述
Attention
Soft Attention
1 | K. Xu, J. Ba, K. Ryan et al., “Show, attend and tell: neural image caption generation with visual attention,” in Proceedings of the IEEE Conference on Computer Vision and |
Hard Attention
1 | K. Xu, J. Ba, K. Ryan et al., “Show, attend and tell: neural image caption generation with visual attention,” in Proceedings of the IEEE Conference on Computer Vision and |
Multihead Attention (Transformer)
1 | A. Vaswani, N. Shazeer, N. Parmar et al., “Attention is all you need,” in Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, December 2017. |
Scaled Dot-Product Attention (Transformer)
1 | A. Vaswani, N. Shazeer, N. Parmar et al., “Attention is all you need,” in Proceedings of the Neural Information Processing Systems, Long Beach, CA, USA, December 2017. |
Global Attention
1 | L. Minh-Thang, H. Pham, and C. D. Manning, “Effective approaches to attention-based neural machine translation,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, September 2015. |
Local Attention
1 | L. Minh-Thang, H. Pham, and C. D. Manning, “Effective approaches to attention-based neural machine translation,” in Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, September 2015. |
Adaptive Attention with Visual Sentinel
1 | J. Lu, C. Xiong, D. Parikh, and R. Socher, “Knowing when to look: adaptive attention via a visual sentinel for image captioning,”in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 3242–3250, Las Vegas, NV, USA, June-July 2016. |
Semantic Attention
1 | Q. You, H. Jin, Z. Wang, C. Fang, and J. Luo, “Image captioning with semantic attention,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 4651–4659, Las Vegas, NV, USA, June-July 2016. |
Spatial and Channel-Wise Attention
1 | L. Chen, H. Zhang, J. Xiao et al., “SCA-CNN: spatial and channel-wise attention in convolutional networks for image captioning,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), pp. 6298–6306, Las Vegas, NV, USA, June-July 2016. |
Areas of Attention
1 | M. Cornia, L. Baraldi, G. Serra, and R. Cucchiar, “Visual saliency for image captioning in new multimedia services,” in Proceedings of the IEEE International Conference on Multimedia & Expo Workshops (ICMEW), pp. 309–314, Hong Kong, China, July 2017. |
Deliberate Attention
1 | L. Gao, K. Fan, J. Song, X. Liu, X. Xu, and H. Shen, “Deliberate attention networks for image captioning,” in Proceedings of the AAAI Conference on Artificial Intelligence, vol. 33, pp. 8320–8327, Honolulu, HI, USA, January-February 2019. |
Dataset
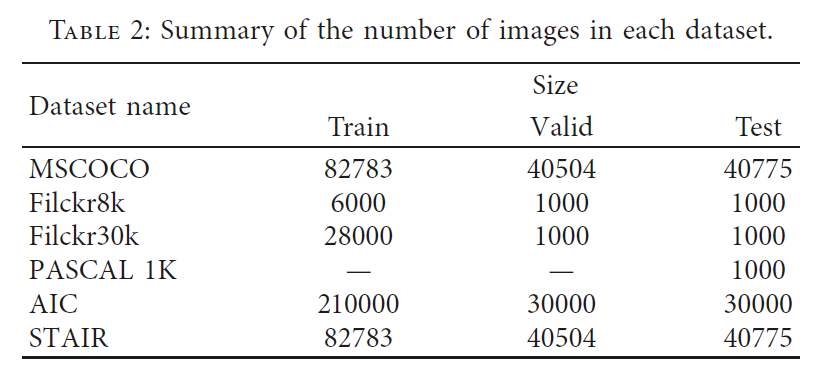
MSCOCO
Microsoft COCO Captions dataset , developed by the Microsoft Team that targets scene understanding, captures images from complex daily scenes and can be used to perform multiple tasks such as image recognition, segmentation, and description.
The dataset uses Amazon’s “Mechanical Turk” service to artificially generate at least five sentences for each
image, with a total of more than 1.5 million sentences. The training set contains 82,783 images, the validation set has 40,504 images, and the test set has 40,775 images. Its 2014 version of the data has a total of about 20G pictures and about 500M of annotation files which mark the correspondence between one image and its descriptions.
Flickr8k/Flickr30k
Flickr8k image comes from Yahoo’s photo album site Flickr, which contains 8,000
photos, 6000 image training, 1000 image verification, and 1000 image testing. Flickr30k contains 31,783
images collected from the Flickr website, mostly depicting humans participating in an event. The corresponding manual label for each image is still 5 sentences.
PASCAL 1K
A subset of the famous PASCAL VOC challenge image dataset, which provides a standard image annotation dataset and a standard evaluation system. The PASCAL VOC photo collection consists of 20 categories, and for its 20 categories, 50 images were randomly selected for a total of 1,000 images. Then, Amazon’s Turkish robot service is used to manually mark up five descriptions for each image. The dataset image quality is good and the label is complete, which is very suitable for testing algorithm performance.
AIC
0e Chinese image description dataset, derived from the AI Challenger, is the first large Chinese description dataset in the field of image caption generation. The dataset contains 210,000 pictures of training sets and 30,000 pictures of verification sets. Similar to MSCOCO, each picture is accompanied by 5 Chinese descriptions, which highlight important information in the image, covering the main characters, scenes, actions, and other contents. Compared with the English datasets common to similar scientific research tasks, Chinese sentences usually have greater flexibility in syntax and lexicalization, and the challenges of algorithm implementation are also greater.
STAIR
The Japanese image description dataset, which is constructed based on the images of the MSCOCO dataset. STAIR consists of 164,062 pictures and a total of 820,310 Japanese descriptions corresponding to each of the five pictures. It is the largest Japanese image description dataset.
Evaluation Criteria
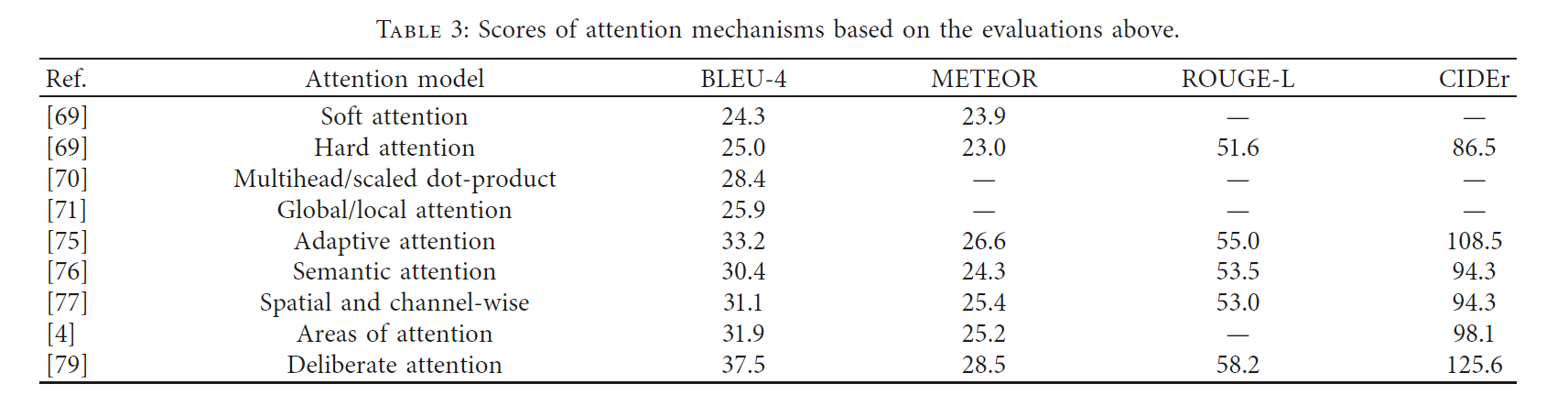
For five indicators, BLEU and METEOR are for machine translations, ROUGE is for automatic summary, and CIDEr and SPICE are present for image caption. They measured the consistency of the n-gram between the generated sentences, which was affected by the significance and rarity of the n-gram. At the same time, all four indicators can be directly calculated by the MSCOCO title assessment tool. The source code is publicly available.
BLEU
It is the most widely used evaluation indicator; the original intention of the design is not for the image
caption problem, but for the machine translation problem based on the accuracy rate evaluation. It is used to analyze the correlation of n-gram between the translation statement to be evaluated and the reference translation statement. Its core idea is that the closer the machine translation statement is to a human professional translation statement, the better the performance. In this task, the processing is the same as
machine translation: multiple images are equivalent to multiple source language sentences in the translation. The higher the BLEU score, the better the performance.
- The advantage of BLEU is that the granularity it considers is an n-gram rather than a word, considering longer matching information.
- The disadvantage of BLEU is that no matter what kind of n-gram is matched, it will be treated the same. For example, the importance of verb matching should be intuitively greater than the article.
METEOR
METEOR is also used to evaluate machine translation, which aligns the translation generates from the model with the reference translation and matches the accuracy, recall, and F-value of various cases. What makes METEOR special is that it does not want to generate very “broken” translations and the method is based on the precision of one gram and the harmonic mean of the recall. The weight of the recall is a bit higher than the precision. This criterion also has features that are not available in others. It is designed to solve some of the problems with BLEU. It is highly relevant to human judgment and, unlike BLEU, it has a high correlation with human judgment not only at the entire collection but also at the sentence and segment level. The higher the METEOR score, the better the performance.
ROUGE
ROUGE is a set of automated evaluation criteria designed to evaluate text summarization algorithms.
The higher the ROUGE score, the better the performance.
CIDEr
CIDEr is specifically designed for image annotation problems. It measures the consistency of image annotation by performing a Term Frequency-Inverse Document Frequency (TF-IDF) weight calculation for each n-gram. This indicator treats each sentence as a “document,” represents it in the form of a TF-IDF vector, and then calculates the cosine similarity of the reference description to the description generated by the model as a score. In other words, it is the vector space model. This indicator compensates for one of the disadvantages of BLEU, that is, all words on the match are treated the same, but in fact, some words should be more important. Again, the higher the CIDEr score, the better the performance.
SPICE
It is a semantic evaluation indicator for image caption that measures how image titles effectively recover objects, attributes, and relationships between them. On the natural image caption dataset, SPICE is better able to capture human judgments about the model’s subtitles, rather than the existing n-gram metrics.