Oscar: Object-Semantics Aligned Pre-training for Vision-Language Tasks
Oscar: Object-Semantics Aligned Pre-training
The code and pre-trained models are released: https://github.com/microsoft/Oscar
We pre-train an Oscar model on the public corpus of 6.5 million text-image pairs, and fi ne-tune it on downstream tasks, creating new state-of-the-arts on six well-established vision-language understanding and generation tasks.
Introduction
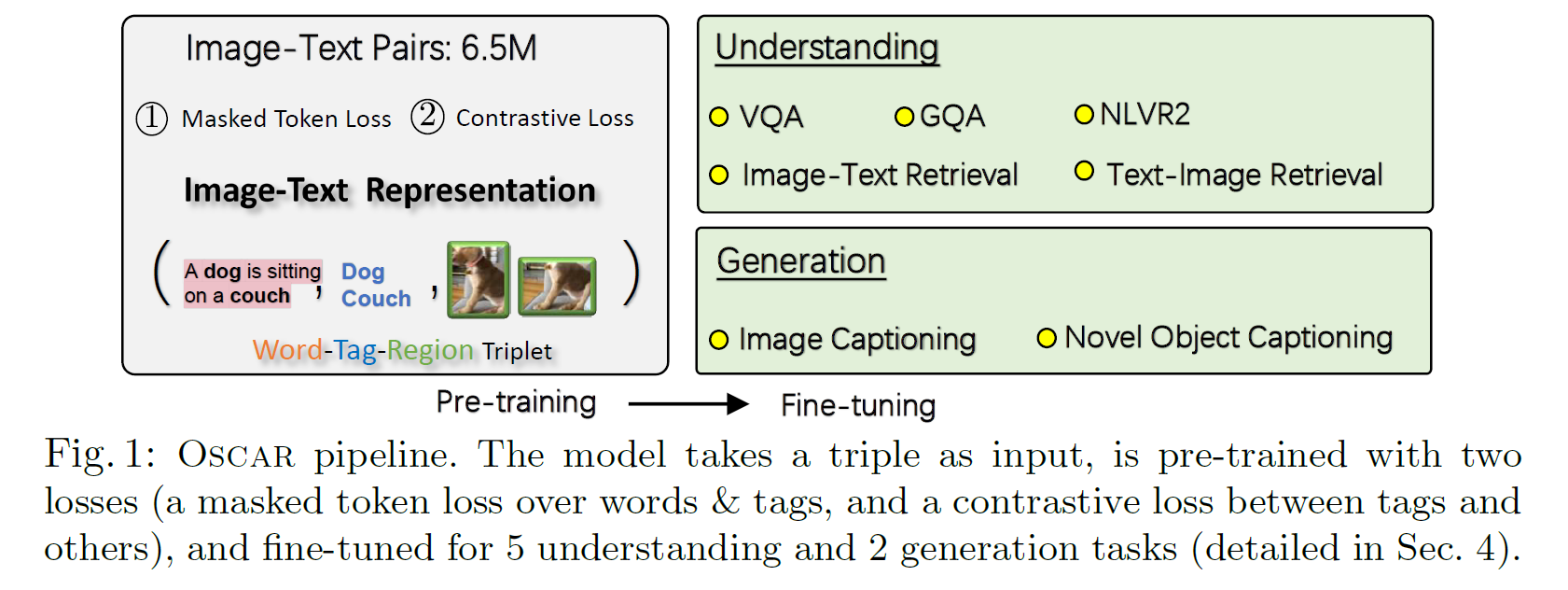
Oscar模型使用目标检测得到的object tags作为anchor points来帮助进行image-text的语义对齐。输入为一个三元组,包含a word sequence, a set of object tags, and a set of image region features,表示为$(w,q,v)$。
预训练得到的模型可以通过fine tune应用于下游的跨模态任务,包括 5 understanding tesks、2 generation tesks。
模型在6.5M Image-text pairs上进行了预训练,语料库来自于现有的V+L数据集,包括COCO、CC、SBUcaptions、flickr30k、GQA等

contribution
- We introduce Oscar, a powerful VLP method to learn generic image-text representations for V+L understanding and generation tasks.
- We have developed an Oscar model that achieves new SoTA on multiple V+L benchmarks, outperforming existing approaches by a signi cant margin
- We present extensive experiments and analysis to provide insights on the effectiveness of using object
tags as anchor points for cross-modal representation learning and downstream tasks.
Background
dataset:$D={(I_i,w_i)}^{N}_{i=1}$ ,The goal of pre-training is to learn cross-modal representations of image-text pairs in a self-supervised manner
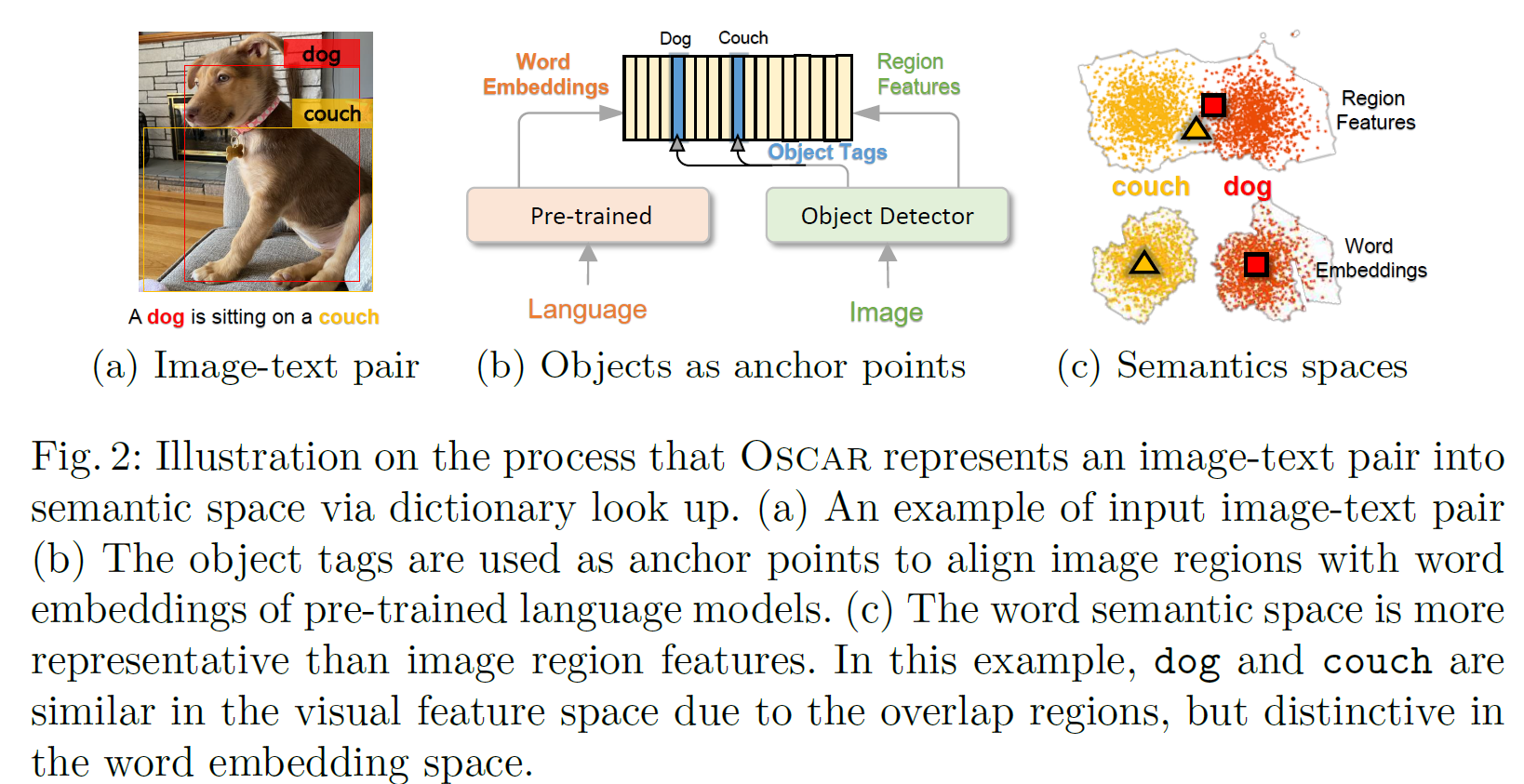
Existing VLP methods take visual region features $v={v_1,···,v_K}$ of an image and word embeddings $w={w_1,···,w_T}$ of its paired text as input, and relies on the self-attention mechanism to learn image-text alignments and produce cross-modal contextual representations.
现有的VLP方法存在两个问题:
- Ambiguity. 由于图像位置的重叠,导致提取的visual embeddings有歧义,如上图(a)中的dog和couch。
- Lack of grounding. VLP是弱监督学习,因为图像区域和文本单词之间并没有明确的对齐方式。但一般图像中的显著目标会同时出现在image和对应的text中,因此可用作anchor points来帮助对齐。
从上图(c) 中可以看出,dog和couch由于在图像中重叠面积较大,在Region Feature中距离较近,不好区分。但在Word Embedding中距离较远,更好区分。
Oscar Pre-training

Input
输入为Word-Tag-Image三元组,表示为$(w,q,v)$,$w$ 是文本序列的embedding,$q$ 是被检测物体文本表示的embedding,$v$ 是region vector的集合。
现有的VLP方法一般将$(w,v)$ 作为输入,Oscar为了便于图文对齐,引入了$q$ 作为anchor points.
$v$ 和$q$ 的产生过程如下。对于有K个目标的图像,用Faster R-CNN提取每个区域的视觉语义$(v^{‘},z)$ ,$v^{‘}$ 是region feature,为P (2048) 维向量,$z$ 为region position,为R (4 or 6) 维向量,通过将其拼接,得到位置敏感的区域特征向量,将其通过线性投影转化为 $v$,从而使其和word embedding的维度保持一致。$q$ 为被检测目标的文本embedding。
Pre-Training Objective
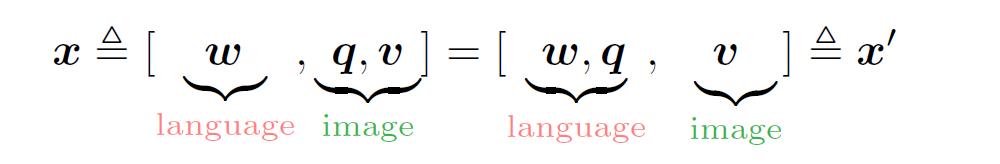
A Dictionary View: Masked Token Loss
$x^{‘}$ 是dictionary view,从这个角度,$w、q$ 均为word embedding表示,share the same linguistic semantic sapce;while $v$ lie in the visual semantic space.
We defi ne the discrete token sequence as $h\triangleq [w,q]$, and apply the Masked Token Loss (MTL) for pre-training. At each iteration, we randomly mask each input token in $h$ with probability 15%, and replace the masked one $h_i$ with a special token $[MASK]$. The goal of training is to predict these masked tokens based on their surrounding tokens $h_{\backslash i}$ and all image features $v$ by minimizing the negative log-likelihood:
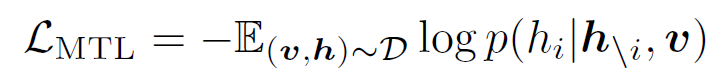
A Modality View: Contrastive Loss
For each input triple, we group $h^{‘}\triangleq [q,v]$ to represent the image modality, and consider $w$ as the language modality. We then sample a set of “polluted” image representations by replacing $q$ with probability 50% with a different tag sequence randomly sampled from the dataset $D$. Since the encoder output on the special token $[CLS]$ is the fused vision-language representation of $(h^{‘},w)$ , we apply a fully-connected (FC) layer on the top of it as a binary classi er $f(.)$ to predict whether the pair contains the original image representation (y = 1) or any polluted ones (y = 0). The contrastive loss is de ned as
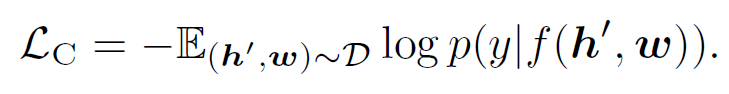
The full pre-training objective of Oscar is:
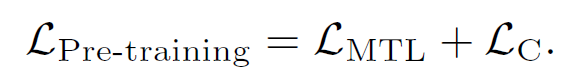
Implementation Details
作者训练了两种模型:$Oscar_B$ and $Oscar_L$ ,分别用BERT base (H=768)和BERT large (H=1024)初始化参数,表示为$\theta_{BERT}$。同时,为了保证图像区域特征和 BERT有同样的 input embedding size,将上述提到的position-sensitive region features 进行linear projection,通过矩阵 $W$ 实现。
因此可训练的参数可表示为 $\theta={\theta_{BERT},W}$。
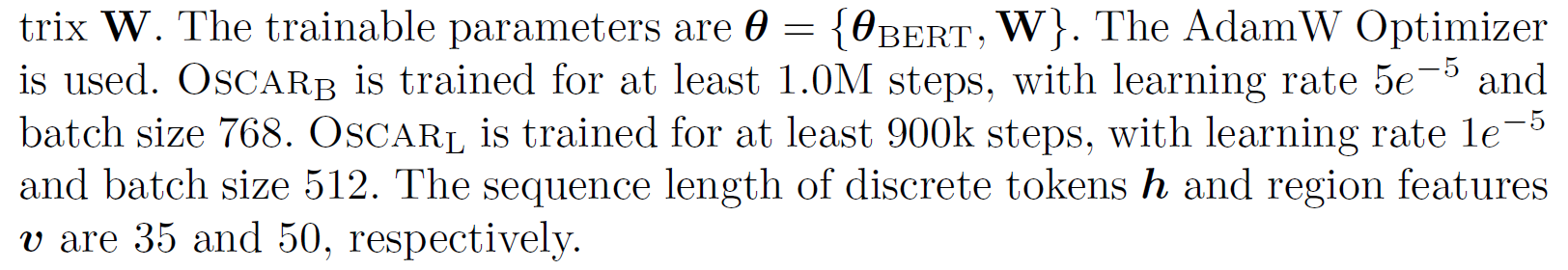
Adapting to Image Captioning
The input samples are processed to triples consisting of image region features, captions, and object tags, in the same way as that during the pre-training. We randomly mask out 15% of the caption tokens and use the corresponding output representations to perform classi cation to predict the token ids. Similar to VLP, the self-attention mask is constrained such that a caption token can only attend to the tokens before its position to simulate a uni-directional generation process. Note that all caption tokens will have full attentions to image regions and object tags but not the other way around.
During inference, we first encode the image regions, object tags, and a special token $[CLS]$ as input. Then the model starts the generation by feeding in a $[MASK]$ token and sampling a token from the vocabulary based on the likelihood output. Next, the $[MASK]$ token in the previous input sequence is replaced with the sampled token and a new $[MASK]$ is appended for the next word prediction. The generation process terminates when the model outputs the $[STOP]$ token. We use beam search (i.e., beam size = 5) in our experiments and report our results on the COCO image captioning dataset.
Results
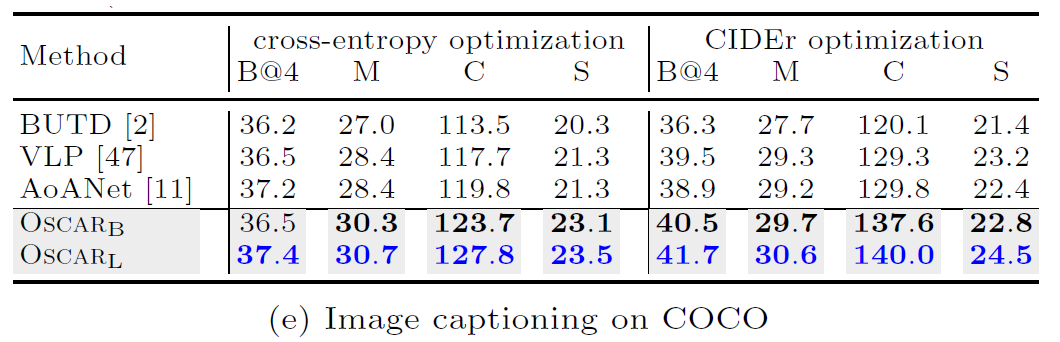
为了考虑参数的利用效率,我们在下表 1 中比较了不同大小的模型。Oscar 在六项任务上均达到了最新水平。在大多数任务上,我们的基本款模型(base model)要优于以前的大型模型(large model),通常情况下会大大提高。
它表明 Oscar 具有很高的参数利用效率,我们认为部分原因是物体的使用大大简化了图像和文本之间语义对齐的学习。


我们使用 t-SNE 可视化工具,把 COCO 测试集的图像-文本对的语义特征空间画在了二维平面上。对于每个图像区域和单词序列,我们将其传递通过模型,并将其最后一层输出用作特征。比较带有和不带有物体标签的预训练模型。
图 4 中的结果揭示了一些有趣的发现。第一个发现是关于同一个物体的两种不同模态的:借助对象标签,可以大大减少两个模态之间同一对象的距离。
例如,Oscar 中 Person 的图片和文本表示比基线方法中的视觉表示和文本表示更接近,这个在图 4 中用红色曲线表示。
第二个发现是不同物体间的:添加物体标签后,具有相关语义的对象类越来越接近(但仍可区分) 而这在基线方法中有些混合,例如图 4 中用灰色曲线表示的动物(zebra, elephant, sheep等)。
这证明了物体标签在学习对齐语义中的重要性:物体被用做定位点链接和规范化了跨模式的特征学习。