Paddle目标检测
V1.8
1 | paddlepaddle 1.8.3 |
预测
测试图像:

代码(calParams可以计算参数量):
1 | import os |
结果:

V2.0.2
1 | paddlepaddle-gpu 2.0.2 |
finetune
参考文档:目标检测全流程教程
自定义数据集
VOC格式
首先官网文档中给出的说法不一,在目标检测全流程教程中,在准备数据一栏,指出VOC格式数据集的文件组织结构为:
1 | ├── annotations |
而在如何训练自定义数据集和如何准备训练两个文档中,指出VOC格式数据集的文件组织结构为:
1 | VOCdevkit |
需要进行的处理为:
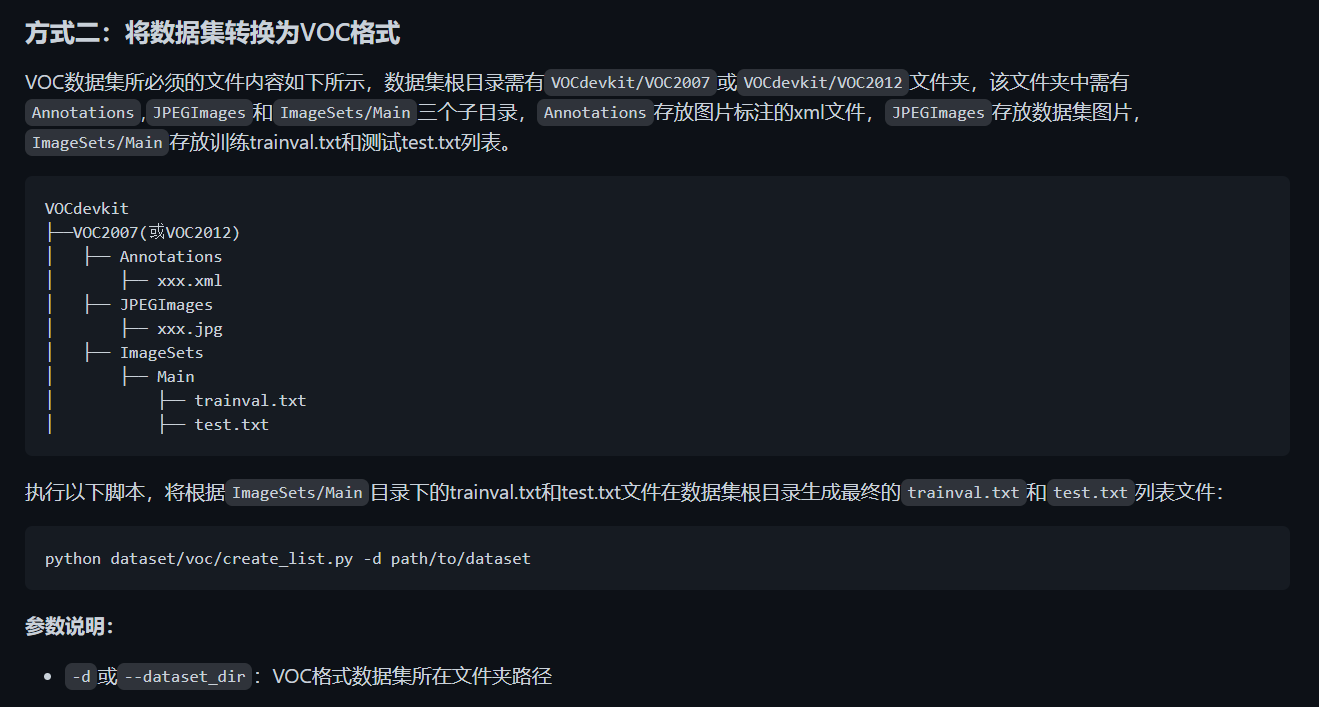
总结:
没有必要一定按照VOC原始格式组织文件,即文件夹名字不必遵从Annotaions、ImageSets、JPEGImages这种严格命名,且原本保存在ImageSets/Main下的test.txt、train.txt、val.txt等文件都可以不要,但在数据集根目录下(VOC2007)必须有train.txt、test.txt文件
如果严格按照VOC格式,数据集最好整理成以下结构:
1 | VOCdevkit |
其中ImageSets/Main下面的trainval.txt、test.txt仅包含文件名(不含后缀),例如:
1 | c000001 |
而根目录下的train.txt、val.txt应包含图片和xml文件的相对路径:
1 | JPEGImages/train/c000001.jpg Annotations/train/c000001.xml |
注意,以上路径前不要加’./‘,即不要变成 ./JPEGImages/train/c000001.jpg这种形式
xml
xml文件应处理成以下格式:
1 | <annotation> |
object中,difficult为必含项,如果原本的xml不含difficult,通过以下代码添加:
1 | import xml.etree.ElementTree as ET |
安装环境
参考文档:安装说明
按照说明安装即可,PaddleDetection必须要在cd到clone下的目录运行,不是一个pip库。
NCCL安装(give up)
下载地址:nccl
本地安装库
选择对应的本地安装库:
安装储存库:sudo dpkg -i xxxxxxxx.deb
更新apt库:sudo apt update
安装:sudo apt install libnccl2=2.9.6-1+cuda11.0 libnccl-dev=2.9.6-1+cuda11.0
网络安装库
首先执行命令
1
2sudo apt-key adv --fetch-keys https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/7fa2af80.pub
sudo add-apt-repository "deb https://developer.download.nvidia.com/compute/cuda/repos/ubuntu1804/x86_64/ /"`提示 No module named ‘apt_pkg’,解决方法:no module named apt_pkg ,执行1,2即可
之后提示 cannot import name ‘_gi’ from ‘gi’, 解决方法:cannot import name ‘_gi’
之后apt update报错如下:

试了几种解决方法,只有一种有用:solution
安装ping命令,接着
ping developer.download.nvidia.com可以找到对应的ip地址,将地址添加到hosts文件中:45.43.38.238 developer.download.nvidia.cnncll tests
1
2
3git clone https://github.com/NVIDIA/nccl-tests.git
make
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 4
修改配置文件
根据configs下的某一配置文件进行修改,只有就保存到configs文件夹下,比如根据 configs/faster_rcnn_r50_fpn_1x.yml 进行修改,另存为underwater.yml。
max_iters。 max_iters为最大迭代次数,而一个iter会运行
batch_size * device_num张图片。注意:
(1)LearningRate.schedulers.milestones需要随max_iters变化而变化。(2)
milestones设置的是在PiecewiseDecay学习率调整策略中,在训练轮数达到milestones中设置的轮数时,学习率以gamma倍数衰减变化。
(3) 1x表示训练12个epoch,1个epoch是将所有训练数据训练一轮。由于YOLO系列算法收敛比较慢,在COCO数据集上YOLO系列算法换算后约为270 epoch,PP-YOLO约380 epoch。根据实际情况修改max_iters,并参照如何训练自定义数据集下的demo,修改其他参数,如milestones、base_lr
根据数据集格式修改mertic,这里修改为VOC
snapshot_iter,多少iter保存一次模型
weights参数, weights 参数用于设置评估预测使用的模型路径,这里可以是远程路径。
本地路径是指以pdparams为后缀的模型权重文件。注意,这里说的是路径具体到了这一个权重文件,所以只写到文件夹是不够的,比如模型保存到
output/underwater,在此路径下有以下几个文件:model_final.pdmodel、model_final.pdopt(优化相关)、model_final.pdparams(模型权重),则weights必须设置为:output/underwater/model_final一定要写到model_final
num_classes, 模型中分类数 num_classes 模型中分类数量。注意在FasterRCNN中,需要将
with_background=true 且 num_classes=数据num_classes + 1
最后对Reader进行设置:
1 | TrainReader: |
对于TrainReader、EvalReader这里的anno_path用的是相对路径,也就是在根目录下面的train.txt和val.txt,而TestReader中的anno_path一定不能省略,不然infer的时候无法加载出label_list。
EvalReader下一定要手动添加以下代码(在faster_rcnn_r50_fpn_1x.yml源文件中没有),不然评估的时候会报错
1
2inputs_def:
fields: ['image', 'im_info', 'im_id', 'im_shape', 'gt_bbox', 'gt_class', 'is_difficult']
其他参数见目标检测全流程教程
underwater_fasterrcnn
基于 faster_rcnn_r50_fpn_1x.yml
1 | architecture: FasterRCNN |
训练
python3 tools/train.py -c configs/underwater.yml -o ues_gpu=false --eval
命令行中可以通过-o设置配置文件里的参数内容
1 | export CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 |
评估、预测
参考文档:评估、预测
评估:
1 | 设置 save_prediction_only=true,会在当前文件夹下生成预测结果文件bbox.json |
预测:
1 | python3 tools/infer.py -c configs/underwater.yml -o weights=output/underwater/model_final --infer_img=../underwater/dataset/test-A-image/000001.jpg |
预测后会在output文件夹下生成一张图片
GPU+infer_dir:
1 | CUDA_VISIBLE_DEVICES=3 python3 tools/infer.py -c configs/underwater.yml -o weights=output/underwater/best_model use_gpu=true --infer_dir=../underwater/dataset/test-A-image/ |
源码修改
PaddleDetection/ppdet/utils/coco_eval.py
1
2
3第342行,coco_res中添加[xmin, ymin, xmax, ymax]格式的box:
'xxyy_bbox': [xmin, ymin, xmax, ymax]PaddleDetection/tools/infer.py
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17第42行,引用clip_bbox函数
from ppdet.utils.coco_eval import clip_bbox
第227行,添加输出csv的代码:
import pandas as pd
# print(image_path)
# print(bbox_results)
df = pd.DataFrame(columns=('name', 'image_id', 'confidence', 'xmin', 'ymin', 'xmax', 'ymax'))
df_image_id = str(image_path.split('/')[-1].split('.')[0])
for i in bbox_results:
df_temp_name = catid2name[i['category_id']]
# 注意h,w是反过来的
xmin, ymin, xmax, ymax = clip_bbox(i['xxyy_bbox'],[image.size[1], image.size[0]])
df.loc[len(df)] = [df_temp_name, df_image_id, i['score'], int(xmin), int(ymin), int(xmax), int(ymax)]
df.to_csv('/home/paddle2.0/PaddleDetection/output/result.csv', mode='a', header=False, index = False)