MapReduce的编程方法与实践
MapReduce框架
MapReduce将复杂的,运行大规模集群上的并行计算过程高度地抽象两个函数:Map和Reduce
MapReduce采用“分而治之”策略,将一个分布式文件系统中的大规模数据集,分成许多独立的分片。这些分片可以被多个Map任务并行处理。
MapReduce设计的一个理念就是“计算向数据靠拢”,而不是“数据向计算靠拢”,原因是,移动数据需要大量的网络传输开销
MapReduce框架采用了Master/Slave架构,包括一个Master和若干个Slave,Master上运行JobTracker,Slave运行TaskTracker
Hadoop框架是用JAVA来写的,但是,MapReduce应用程序则不一定要用Java来写。
Mapper
1 | public static class WordCountMapper |
在map阶段,key/value键值对作为输入,产生另外一系列key/value键值对作为中间输出写入本地磁盘。mapreduce框架自动将这些中间数据按照key值进行聚集,key值相同的数据将一起被reduce处理。
建立test1.txt和test2.txt
test1.txt
1 | I am Jack |
test2.txt
1 | I am Rose |
则map阶段得到的结果为
test1.txt
1 | <I,1> |
Reduce
1 | public static class WordCountReducer |
reduce阶段以key及对应的value列表作为输入,经过合并key相同的value值后,产生另外一系列key/value对作为最终输出写入hdfs
map处理完后,得到的KV对会分组保存,key值相同的分为一组,然后传递一个组会调用一次reduce,在词频统计中,同一个单词会分为一组,value的值为1,所以reduceSum += val.get() 统计了每一个单词的个数。
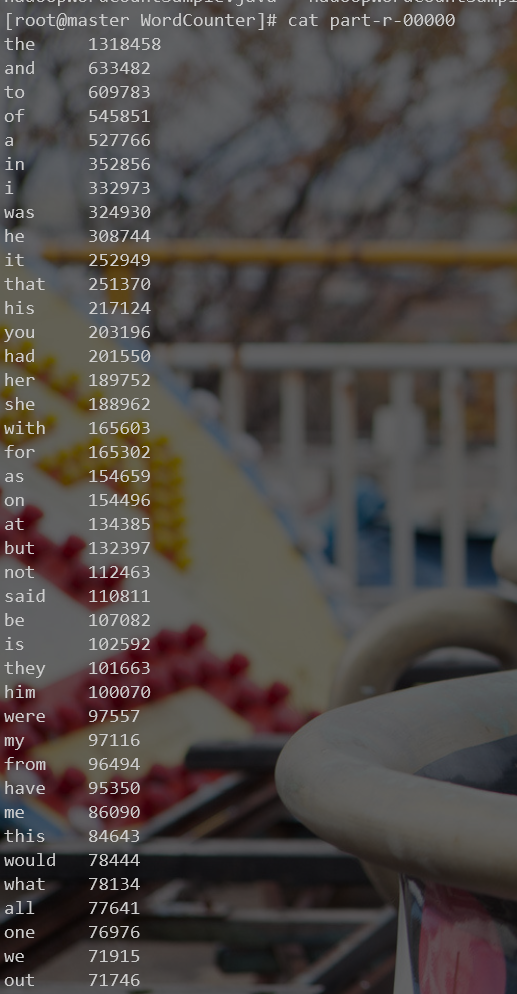
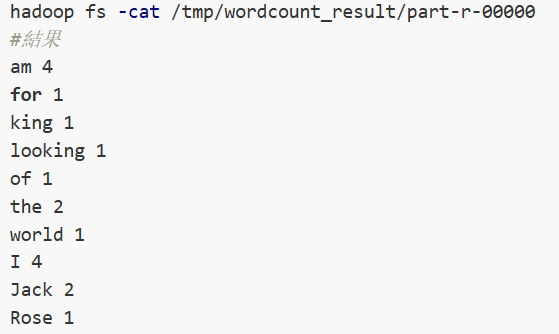
结果:
Sort
由于只需要出现次数最多的100个单词,所以采用TreeMap结构
建立新的sortjob,继承mapper和reducer
mapper
1 | public void map(final Object key, final Text value, final Context context) |
reducer
1 | public void reduce(final Text key, final Iterable<IntWritable> values, final Context context) |
上传ebooks
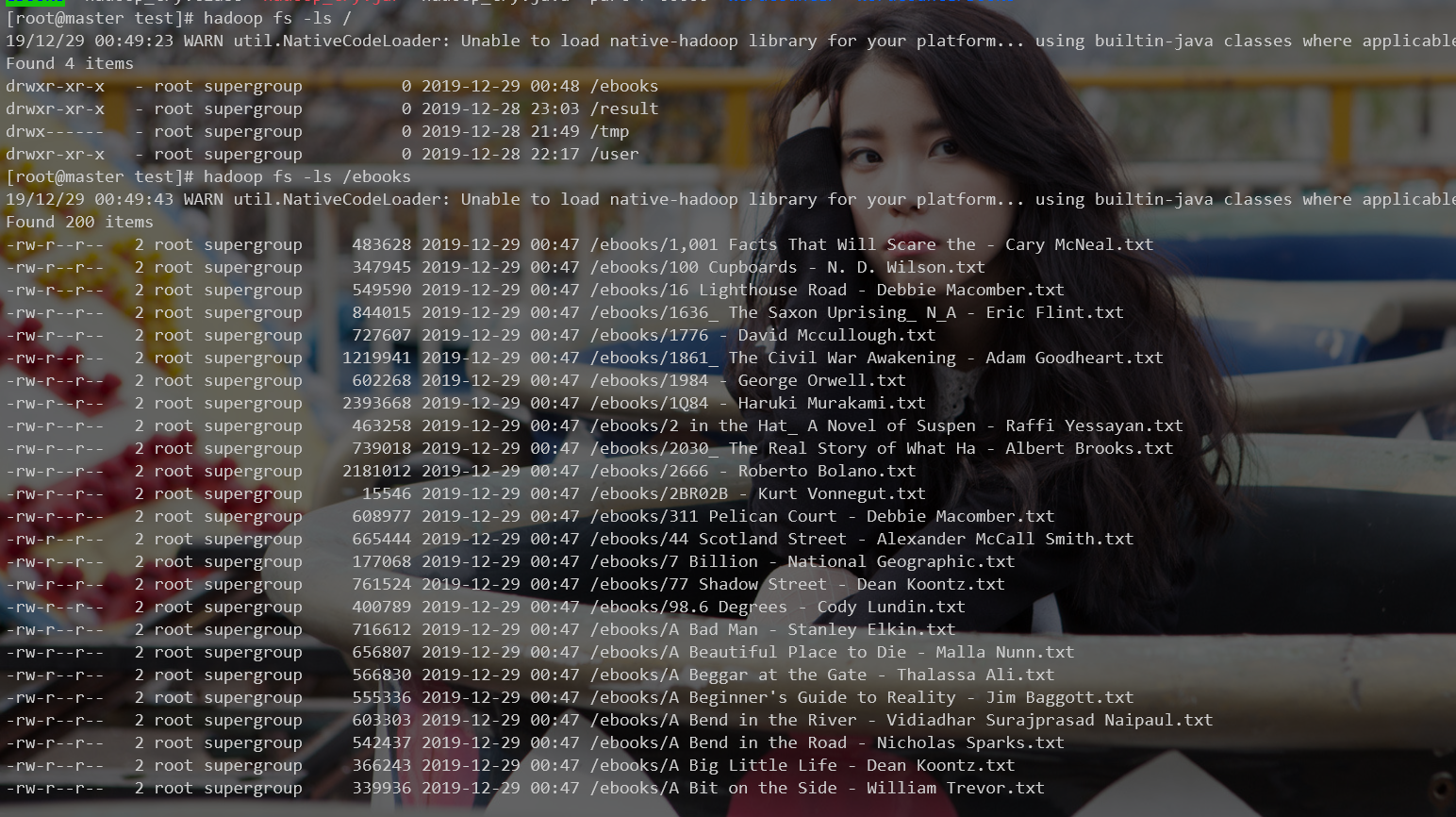
在hdfs根目录建立文件夹ebooks
使用scp将200本英文书上传到虚拟机:
hadoop fs -put /ebooks / 将文件上传到hdfs目录下
可以看到文件上传成功
运行
编辑run.sh
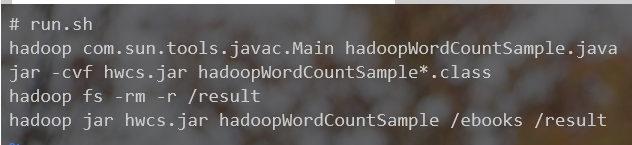
编译后的结果:

第一次运行时,在运行过程中会被强制kill掉进程,返回码为137
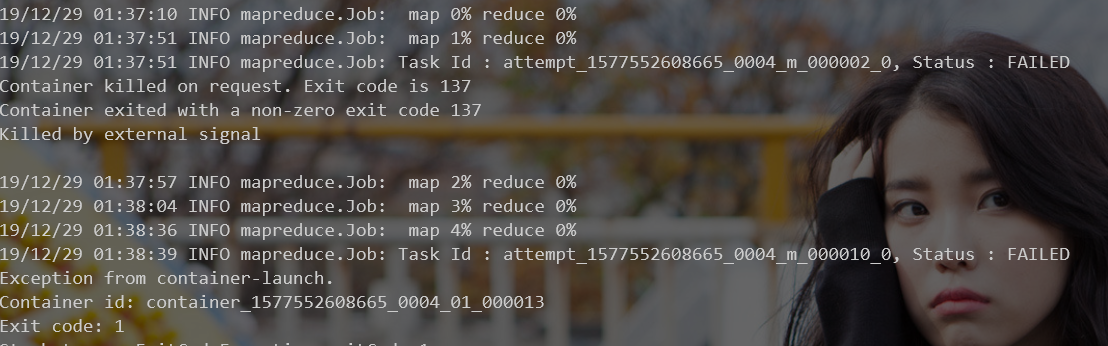
原因是内存分配不足造成,需要修改配置文件
yarn-site.xml ,添加以下内容
1 | <property> |
mapred-site.xml ,添加以下内容
1 | <property> |
result